Object detection
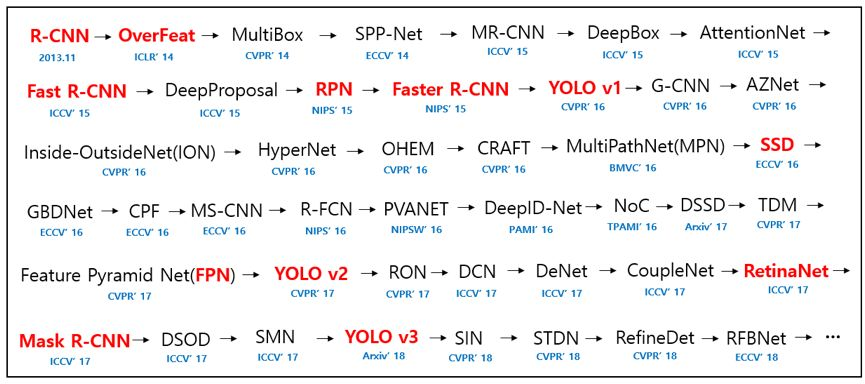
| one-stage系 | two-stage系 | anchor-free系 | Transform | Weakly Supervised |
|---|---|---|---|---|
| YOLO V1,V2,V3,V4,V5 | FPN | FCOS | POTO | Co-Mining |
| SSD | RFCN | ATSS | OneNet | SFOD |
| RetinalNet | Lighthead | GFocal Loss v1,v2 | ||
| AutoAssign | ||||
| BorderDet | ||||
| TTFNet | ||||
Anchor Free
FCOS
出发点
解决 Anchor based 算法的缺点:
- 检测性能对于anchor的大小,数量,长宽比都非常敏感
- 为了去匹配GT,需要生成大量的anchor, 造成了样本间的不平衡
- 在训练中,需要计算所有anchor与真实框的IOU,这样就会消耗大量内存和时间
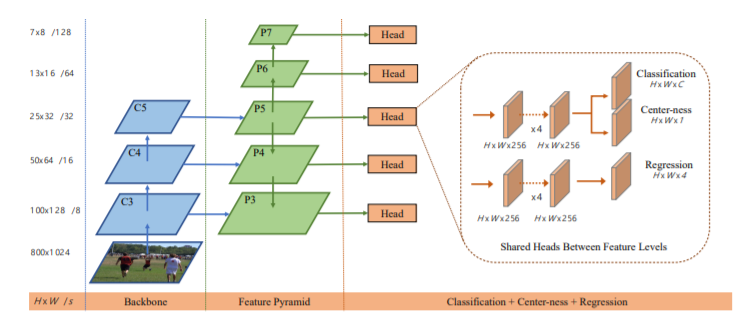
正负样本采样方法
- FCOS直接对不同feature level限制bbox不同的范围(为了解决像素点目标重叠)
- 每个FPN层负责不同大小框的回归, m2, m2, m4, m5, m6, m7负责0, 64, 128, 256, 512, ∞尺寸的GT
- 如果一个location(x, y)落到了任何一个GT box中,那么它就为正样本
- 如果在同一图层仍然出现了重合问题,那么还是按照该点所在最小面积ground truth检测框进行分配

Center-ness
FCOS存在大量的低质量的检测框。这是由于我们把中心点的区域扩大到整个物体的边框,经过模型优化后可能有很多中心离GT box中心很远的预测框,为了增加更强的约束,作者提出了Center-ness的方法来解决这个问题,使用BCE loss对center-ness进行优化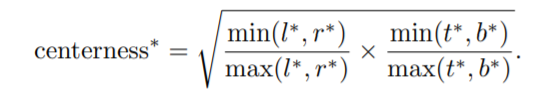
当loss越小时,centerness就越接近1,也就是说回归框的中心越接近真实框
ATSS
出发点
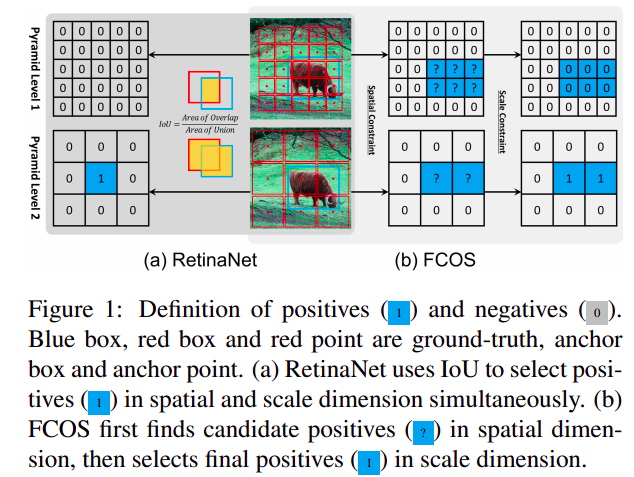
Anchor-based和anchor-free检测器主要的差异是如何定义正负样本
Anchor-based和anchor-free检测器有三点不同:
- 特征图上每个位置的anchor数量不同
- RetinaNet每个位置多个预设的anchor,FCOS每个位置一个anchor point
- 定义正负样本的方式不同
- RetinaNet通过IOU来选择正负样本,FCOS利用空间和尺度约束来选择正负样本
- FCOS相比RetinaNet的AP更高,但如果选择了相似的正负样本采样方法,anchor-based和anchor-free的方法没有显著的差异
- 回归的开始状态不同
- RetinaNet通过anchor来回归目标,FCOS通过anchor point来回归目标(回归的开始状态并不是造成结果差异的原因)
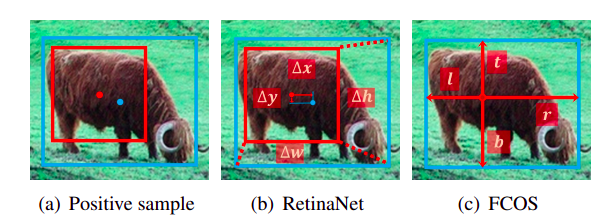
- RetinaNet通过anchor来回归目标,FCOS通过anchor point来回归目标(回归的开始状态并不是造成结果差异的原因)
Adaptive Training Sample Selection (ATSS)
- 基于anchor和GT之间的中心距离来选择候选框
- 使用anchor和GT之间的IoU的mean和std的和作为IoU阈值
一个目标(GT)的IOU mean用于衡量和这个目标关联的anchor对它的匹配度。mean越高,表示这个目标拥有很多高质量的候选框;一个目标的IOU std用于衡量哪个层适合检测这个目标。高std表示存在某个特征层特别适合这个目标,低std表示存在多个特征层适合检测这个目标。
将mean和std加在一起作为IOU阈值,可以自适应的从合适的特征层级为每个目标选择正样本
- 限制正样本的中心在GT内
如果anchor的中心在GT外,那么它会使用目标外的特征来预测,对于训练帮助不大
- 维持不同目标采样数量的公平性
常规的采样方法倾向于采样更多的正样本,而ATSS对于每个目标大约采样$0.2KL$个正样本

BorderDet
出发点
对于dense object detector(e.g. FCOS、FPN的RPN),都是使用simple point特征去预测框的分类和回归,但是发现只用一个点的特征是不够的,很难去捕捉到物体边界的信息来精准定位。这些年有很多研究通过级联的方式,希望通过引入更强的特征来增加simple point特征,主要包括GA-RPN、RepPoints等。但这些工作可能存在两个问题。
- 一些操作(e.g. Deformable Conv)来增强特征,但这些操作可能是冗余的,甚至会引入“有害”的背景信息。
- 这些方法没有显示的提取边界特征,边界极限点特征对边界框的定位比较重要。
如下图,这个运动员中心的五角星位置即为anchor点,但是确定该物体边界框的主要是边界上的四个橘色圆点,这个运动员的边界框的位置主要由四个极限点来确定。用其他的方法可能会引入一些有害的信息,且不能直接有效的提取到真正有用的边界极限点。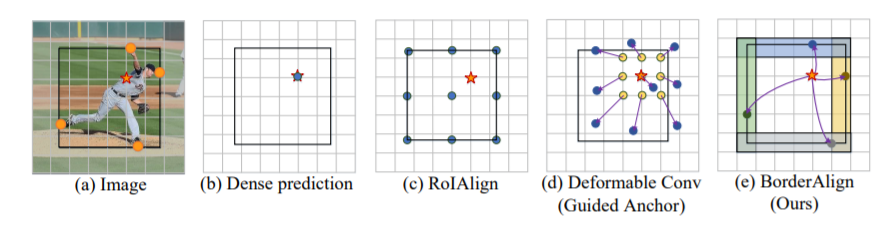
BAM(Border Alignment Module)
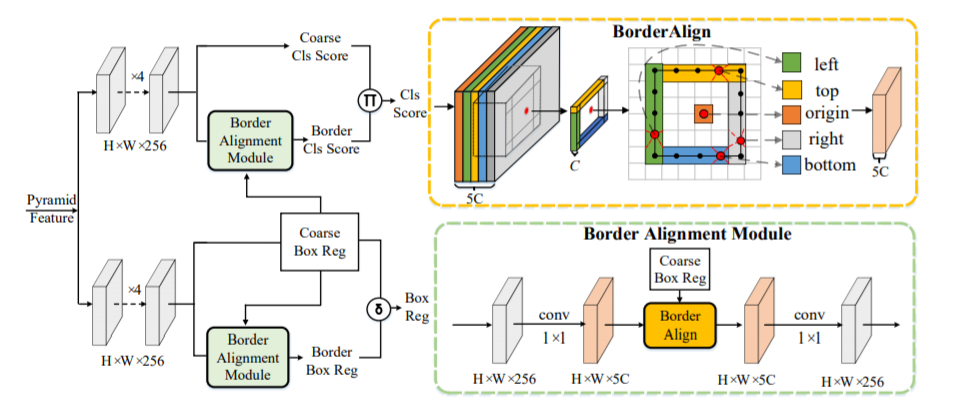
对于一个特征图,通道个数为5xC,这是一个border-sensitive的特征图,分别对应物体4个边界特征和原始anchor点位置的特征。对于一个anchor点预测的一个框,我们把这个框的4个border对应在特征图上的特征分别做pooling操作。且由于框的位置是小数,所以该操作使用双线性插值取出每个border上的特征。如图所示,我们每条边会先选出5个待采样点,再对这5个待采样点取最大的值,作为该条边的特征,即每条边最后只会选出一个采样点作为输出。那么每个anchor点都会采样5个点的特征作为输出,即输出的通道数也为5xC个。
BAM模块需要将FCOS的框位置的输出作为输入,显示的提取该框边界上的特征。最终BAM会分别预测一个border score和border reg,和原始密集检测器的输出组合成为最后的输出。
AutoAssign
通过生成正负权重图来动态地修改每个位置的预测,从而自动地确定正负样本。具体来说,作者提出了一个中心加权模块来调整特定类别的先验分布,并用了一个置信度加权模块来适应每个实例特定的分配策略。整个标签分配过程不需要额外的修改即可在不同数据集和任务上使用
现有检测器对正负位置采样主要是根据的人工先验:
- 基于anchor的检测器如RetinaNet是在每个位置预置几个不同尺度和高宽比的anchor,根据IoU值在不同空间和尺度特征图进行正负样本采样
- FCOS等anchor-free检测器是选取固定比例的中心区域作为每个目标的空间正位置,并根据预定义的尺度约束选取FPN的某一层级。这些检测器都是根据目标的先验分布来设计的分配策略。
但是在现实世界中,目标外观在不同类别和场景之间差异很大。固定的中心采样策略可能会导致目标外部位置分为正值,因为在目标上采样会比在背景采样更容易得到高分类置信度。另一方面,尽管CNN可以学习偏移,但是当将背景标为正样本时,特征移动带来的干扰可能会降低性能。
因此,固定的采样策略可能并不能在空间和尺度维度上选到最合适的位置。作者提出了一种新的标签分配策略。首先遵循FCOS等anchor free方法不使用人工设计的anchor,直接预测每个位置上的目标。为了保留足够多的位置用于进一步的优化,先处理所有尺度层级的边界框(正样本+负样本)中的所有位置。然后生成正负权重图来修正训练损失中的预测。为适应不同类别和域的分布,作者提出了一个类别加权模块,center weighting,用来学习数据中每个类别的分布。为适应每个实例的外观和比例,作者又提出一个置信度加权模块(Confidence weighting),在空间和尺度维度上修改各个位置的正、负置信度。然后将两个模块结合起来,生成所有位置的正、负权重图进行加权,加权过程是可微的,可通过反向传播进行优化。
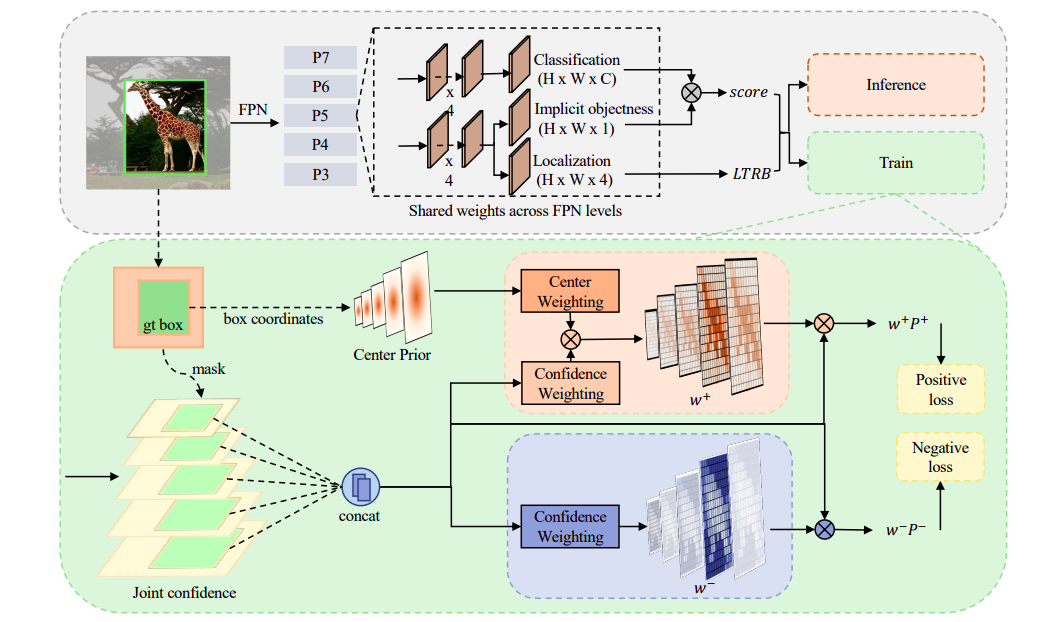
Center Weighting
先验分布是标签分配的基本要素,尤其是在训练早期。通常目标的分布会倾向于中心先验,但不同类别的目标可能会有不同的分布。保持采样中心无法去更好地捕捉现实世界中不同实例的不同分布。对不同类别的目标,更需要一种自适应的中心分布。
因此基于中心先验作者提出了一种带可学习参数的高斯形状的类别级加权函数G,每一类别都有其独有的参数(μ,σ),相同类别的目标共享这一组参数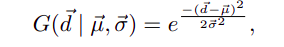
Confidence Weighting
Classification confidence
给定空间位置i,其分类置信度定义为Pi(cls|θ),目标类别概率由网络直接预测,θ表示模型参数。为确保有考虑到所有合适的位置,作者先考虑了框内所有空间位置。由于一个目标很难完全占满预测框,所以初始正集中往往会包含一部分背景。如果一个位置实际是背景,那么该位置所有的类别预测都是不合理的,将这些背景位作为正样本会有损检测性能。
为了抑制来自劣质位的false positives,作者引入了一个Implicit-Obiectness分支。它的工作原理类似于RPN 和YOLO中的Objectness,主要进行前景、背景的二分类任务,但是其存在缺少显式标签的问题。RPN和YOLO采用预定义分配方式,分配一致的正标签,而Autoassign需要动态地去找到并强调那些合适的positive。Implicit-Obiectness分支会和分类分支一起去优化Objectness,因此它不需要显式标签,其实也就是用一个隐式的前景背景二分类对分类预测做一个相乘,这个分支没有额外监督,就只是单纯地去放缩一下分类的预测。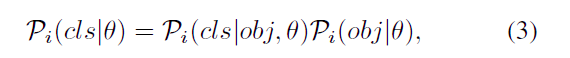
Joint confidence modeling
了生成每个位置的正负无偏估计,除了分类外,还应该考虑到定位置信度。定位分支的输出是框的偏移量,这很难直接用于度量回归置信度。因此作者将定位损失$L_{i}^{cls}(\theta)$
转换为回归似然Pi(loc|θ),然后将分类和回归似然结合起来得到联合置信度Pi(θ),联合置信度可由损失转换得到。为了不失泛化性,作者使用二元交叉篇损失(BCE)用于分类,λ用来平衡两个损失。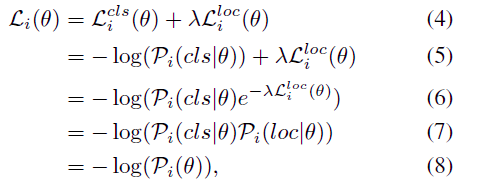
Weighting function
positive weights
对于一个目标i,应该只关注其边界框内合适的位置做出更精准的预测。但是在训练刚开始网络参数是随机初始化的,其预测的置信度值可能并不合理。因此来自先验的指导信息也很重要。对于位置i∈Sn,作者结合了置信度权重模块C(Pi)以及中心加权模块中特定类别的先验$G(di)$来生成positive weights wi+
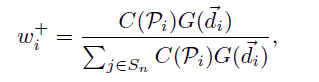
如果一开始质量较差的位置的分类和回归置信度预测出来都不错,那么它的w+就会很高,也就是它权重会较大,监督训练对它的关照会不断增大,这样会导致一些好的位置没有机会翻盘,让网络学成了一个过拟合的模样。所以作者引入了G(d),由于大部分情况下质量较高的正样本都会在框的中心,作者为每个大类学习了一个公共的高斯先验,形状基本是从物体的大致中心区域向外渐渐变弱。引入这一项可学习先验后,那些更有潜力的位置就可能能翻盘。不过这个可学习的先验仅与类别有关,可能会造成对旋转目标的不匹配。为保证竞争和合理的数值范围,还有一个类似softmax的操作,因为本来一个gt框里面也只有一部分是真正地落在物体上的,这些位置应当对应那些较大的w+值。negative weights
边界框内通常会包含一定数量的背景位置,因此我们需要使用加权的negative loss来抑制这些位置,消除false positive。此外,由于边界框内的位置一般会预测得到较高的positive置信度,作者倾向于使用定位置信度来生成false positives的无偏指标。但是负分类并没有参与回归,也就是不应该对其定位置信度做进一步优化。因此作者使用每个位置预测的proposal和GT之间的IoUs来生成负权值wi-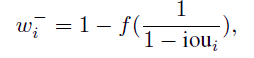
$iou_{i}$表示位置i的propos与所有GT的IOU最大值。为作为有效权重使用,作者通过函数f归一化1/(1-ioui)到0-1之间。这种转换锐化了权值分布,并确保了IoU最高值位置的负损失为0,边界框以外所有位置的wi-设置为1,因为是背景。
Loss function
通过生成正负权重图,作者实现了为每个实例动态分配更合适的空间位置且自动选择合适的FPN层级。由于权重图会对训练损失做贡献,AutoAssign以可微的方式处理标签分配,损失函数为: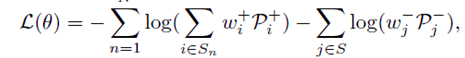
GFocal Loss V1

出发点
classification score 和 IoU/centerness score 训练测试不一致
用法不一致
训练的时候,分类和质量估计各自训记几个儿的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap。对象不一致
借助Focal Loss的力量,分类分支能够使得少量的正样本和大量的负样本一起成功训练,但是质量估计通常就只针对正样本训练。
那么,对于one-stage的检测器而言,在做NMS score排序的时候,所有的样本都会将分类score和质量预测score相乘用于排序,那么必然会存在一部分分数较低的“负样本”的质量预测是没有在训练过程中有监督信号的,有就是说对于大量可能的负样本,他们的质量预测是一个未定义行为。
这就很有可能引发这么一个情况:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面。
- bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty
在复杂场景中,边界框的表示具有很强的不确定性,而现有的框回归本质都是建模了非常单一的狄拉克分布,非常不flexible。我们希望用一种general的分布去建模边界框的表示。如图所示(比如被水模糊掉的滑板,以及严重遮挡的大象)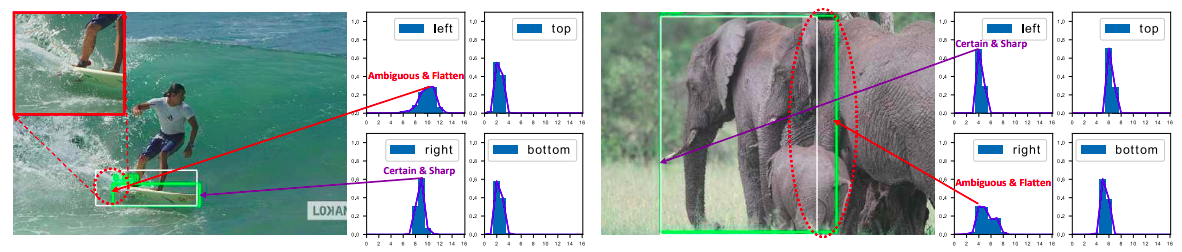
Generalized Focal Loss
为了保证training和test一致,同时还能够兼顾分类score和质量预测score都能够训练到所有的正负样本,那么一个方案呼之欲出:就是将两者的表示进行联合。这个合并也非常有意思,从物理上来讲,我们依然还是保留分类的向量,但是对应类别位置的置信度的物理含义不再是分类的score,而是改为质量预测的score。这样就做到了两者的联合表示
Focal Loss
$
FL(p)=-(1-p_{t})^{\gamma}log(p_{t}),\ p_{t}=
\left{\begin{matrix}
p, when \ y=1 & \
1-p, when \ y=0 &
\end{matrix}\right.
$Quality Focal Loss
$
QFL(\sigma)=-\left |y-\sigma \right |^{\beta}((1-y)log(1-\sigma)+ylog(\sigma))
$
对于框的表示我们选择直接回归一个任意分布来建模框的表示。当然,在连续域上回归是不可能的,所以可以用离散化的方式,通过softmax来实现即可。这里面涉及到如何从狄拉克分布的积分形式推导到一般分布的积分形式来表示框1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Project(nn.Module):
"""
A fixed project layer for distribution
"""
def __init__(self, reg_max=16):
super(Project, self).__init__()
self.reg_max = reg_max
self.register_buffer("project", torch.linspace(0, self.reg_max, self.reg_max + 1))
def forward(self, x):
"""Forward feature from the regression head to get integral result of
bounding box location.
Args:
x (Tensor): Features of the regression head, shape (N, 4*(n+1)),
n is self.reg_max.
Returns:
x (Tensor): Integral result of box locations, i.e., distance
offsets from the box center in four directions, shape (N, 4).
"""
x = F.softmax(x.reshape(-1, self.reg_max + 1), dim=1)
x = F.linear(x, self.project.type_as(x)).reshape(-1, 4)
return x
对于任意分布来建模框的表示,它可以用积分形式嵌入到任意已有的和框回归相关的损失函数上,例如最近比较流行的GIoU Loss。但是如果分布过于任意,网络学习的效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式。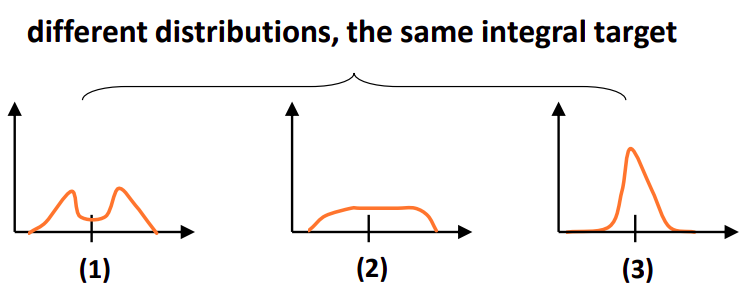
考虑到真实的分布通常不会距离标注的位置太远,所以我们又额外加了个loss,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。
- Distribution Focal Loss
$DFL(S_{i}, S_{i+1})=-((y_{i+1}-y)log(S_{i})+(y-y_{i})log(S_{i+1}))$
其形式上与QFL的右半部分很类似,含义是以类似交叉熵的形式去优化与标签y最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去。
extra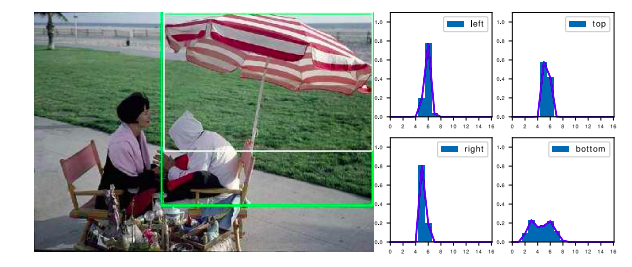
有一些分布式表示学到了多个峰,比如伞这个物体,它的伞柄被椅子严重遮挡。如果我们不看伞柄,那么可以按照白色框(gt)来定位伞,但如果我们算上伞柄,我们又可以用绿色框(预测)来定位伞。
在分布上,它也的确呈现一个双峰的模式(bottom),它的两个峰的概率会集中在底部的绿线和白线的两个位置。这个观察还是相当有趣的。
这可能带来一个妙用,就是我们可以通过分布shape的情况去找哪些图片可能有界定很模糊的边界,从而再进行一些标注的refine或一致性的检查等等。
GFocal Loss V2
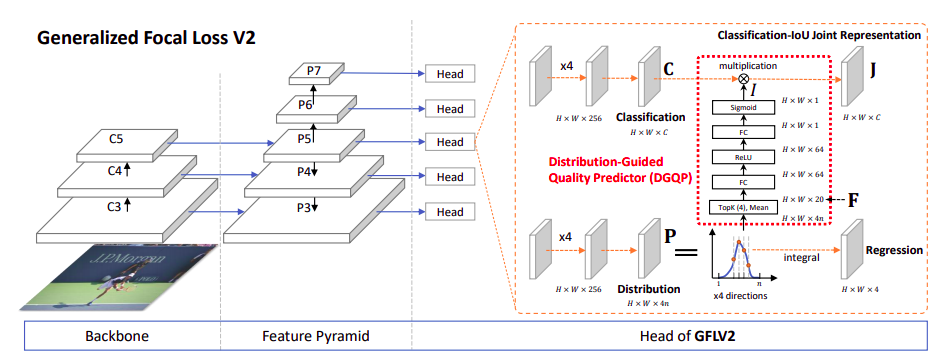
用边界框的不确定性的统计量来高效地指导定位质量估计
a.point:单点特征做增强
b.region:用ROIAlign提取框内所有特征来增强
c.boder:使用边界上所有点的特征来增强
d.middle border:只用边界中心点来增强
e.border align:边界极限点特征对边界框的定位
f.regular sampling points:
g.deformable sampling points: 使用可变性卷积
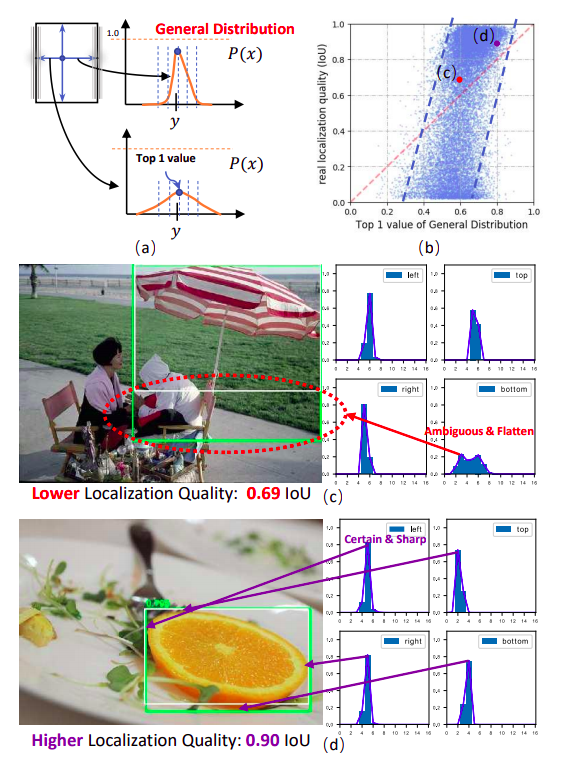
出发点
在GFocalV1中,对边界框进行一个一般化的分布表示建模后基本上那些非常清晰明确的边界,它的分布都很尖锐;而模糊定义不清的边界,它们学习到的分布基本上会平下来,而且有的时候还经常出现双峰的情况。
既然分布的形状和真实的定位质量非常相关,因此用能够表达分布形状的统计量去指导最终定位质量的估计。
对GFLV1做了一些统计分析,具体把预测框的分布的top-1值和其真实的IoU定位质量做了一个散点图,可以看出,整个散点图还是有一个明显地倾向于y=x的趋势的,也就是说,在统计意义上,“分布的形状与真实的定位质量具有较强的相关性”这个假设是基本成立的
v2
直接取学习到的分布(分布是用离散化的多个和为1的回归数值表示的Topk数值。因为所有数值和为1,如果分布非常尖锐的话,Topk这几个数通常就会很大;反之Topk就会比较小。选择Topk还有一个重要的原因就是它可以使得特征与对象的scale尽可能无关,如下图所示
简单来说就是长得差不多形状的分布要出差不多结果的数值,不管它峰值时落在小scale还是大scale。把4条边的分布的Topk concat在一起形成一个维度非常低的输入特征向量(可能只有10+或20+),用这个向量再接一个非常小的fc层(通常维度为32、64),最后再变成一个Sigmoid之后的scalar乘到原来的分类表征中就可以了
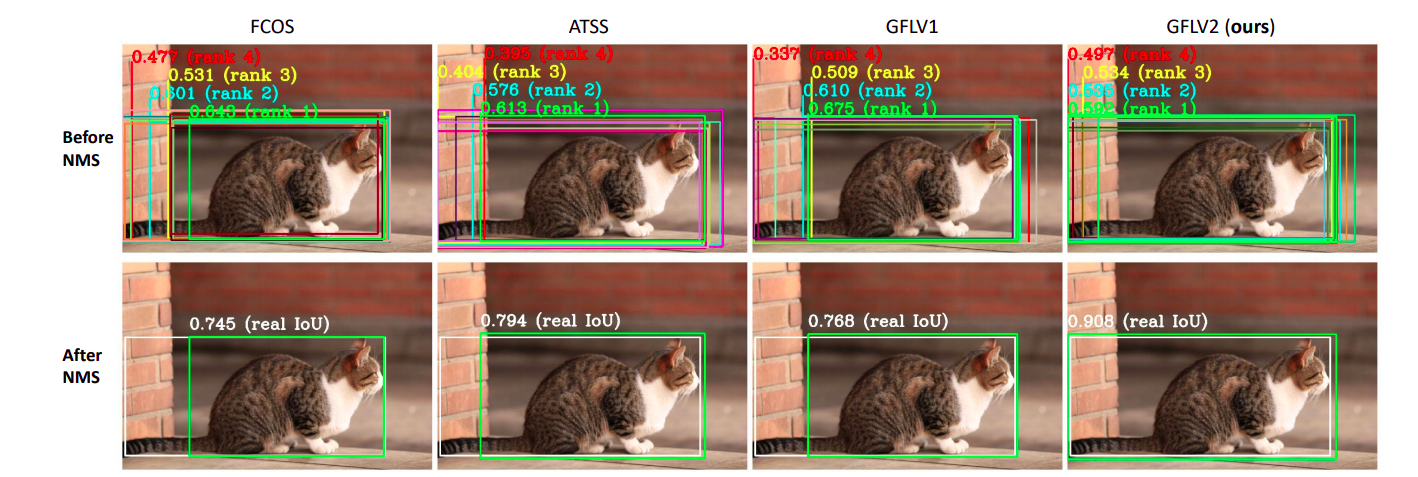
其他算法里面也有非常准的预测框,但是它们的score通常都排到了第3第4的位置,而score排第一的框质量都比较欠佳。相反,GFLV2也有预测不太好的框,但是质量较高的框都排的非常靠前.
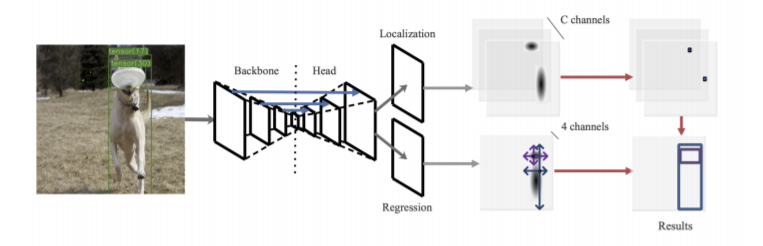
TTFNet
出发点
现有的目标检测很少能同时达到训练时间短、推理速度快、精度高等目的:
- 由于模型简化而难以训练,在很大程度上依赖于数据增强和较长的训练时间。例如centernet需要在公共数据集MSCOCO上进行140个epochs训练。
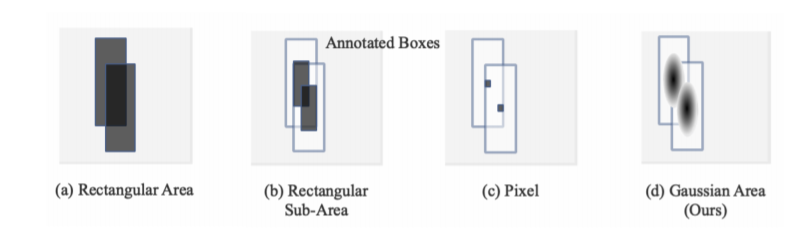
正负样本采样方法
从BBOX框中编码更多的训练样本,主要是增加高质量正样本数,与增加批量大小具有相似的作用,这有助于扩大学习速度并加快训练过程。
主要是通过高斯核函数实现。其实很简单,我们知道centernet的回归分支仅仅在中心点位置计算loss,其余位置忽略,这种做法就是本文说的训练样本太少了,导致收敛很慢,需要特别长的训练时间,而本文采用高斯核编码形式,对中心点范围内满足高斯分布范围的点都当做正样本进行训练,可以极大的加速收敛。本文做法和FCOS非常类似,但是没有多尺度输出,也没有FPN等复杂结构,比较像简化版本的FCOS,属于实践性很强的算法。
将高斯分布概率作为样本权重来加权那些靠近目标中心的样本
结构
TTFNet使用ResNet和DarkNet作为主干网络。 主干网络提取的特征被采样到原始图像的1/4分辨率,这是通过Modulated Deformable Convolution(MDCN)和上采样层实现的。在MDCN层之后是批归一化(BN)和ReLU。上采样的特征然后分别通过两个头部为不同的目标。
检测头在物体中心附近的位置产生高激活,而回归头直接预测从这些位置到box四面的距离。由于目标中心对应于特征映射处的局部最大值,因此可以在2D最大池的帮助下安全地抑制非最大值。然后利用局部最大值的位置来收集回归结果。
最后,可以得到检测结果。 新提出的方法有效地使用了大中型目标中包含的注释信息,但对于包含很少信息的小目标,推广是有限的。为了在较短的训练计划中提高小目标的检测性能,添加了shortcut connections来引入高分辨率但低级别的特征。shortcut connections从主干的2级,3级和4级引入特征,每个连接由3×3卷积层实现。第二、第三和第四阶段的层数设置为3、2和1,除了shortcut connections中的最后一层外,ReLU遵循在每个层。
Weakly Supervised
Co-Mining
Self-Supervised Learning for Sparsely Annotated Object Detection
PAPER ADDRESS
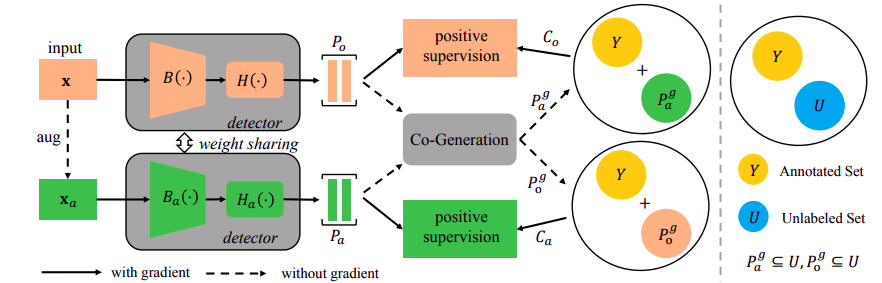
在训练阶段使用共享参数的双检测器分别对原始图片以及增强图片做预测后使用各自预测的正样本(Co-Generation)交叉生成更复杂(完整)的GT来指导网络学习, 属于半监督中解决SAOD问题的。
SAOD: Sparsely Annotated Object Detection
SSOD: Semi-Supervised Object Detection
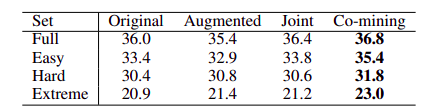
在coco数据集中进行了标注的随机擦除
easy类标注随机删除一个, hard类随机删除一半, extrme类保留一个标注
在SAOD中的增强仅在色域上进行

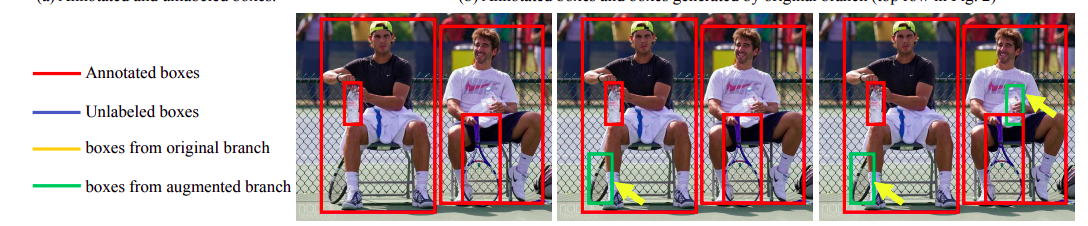
SFOD
A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data
PAPER ADDRESS
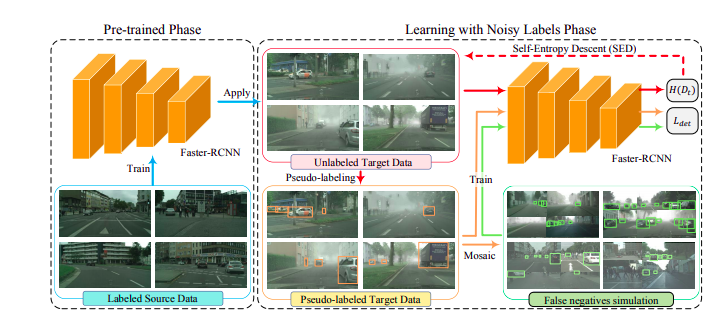
本文首次提出了一种data-free 域自适应目标检测(SFOD)框架,方法是将其建模为带有噪声标签的学习问题。
方法是将其建模为带有噪声标签的学习问题。由于目标域中没有可用的标签,因此很难评估伪标签的质量。在本文中,自熵下降(SED)是一种度量标准,旨在在不使用任何手工标签的情况下搜索适当的置信度阈值以可靠地生成伪标签。尽管如此,仍然无法获得完全清洁的标签。经过全面的实验分析,发现false negatives在所产生的噪声标签中占主导地位。毫无疑问,挖掘FN有助于提高性能,通过像Mosaic这样的数据增强将简单TP其简化为FN Simulation。在四个有代表性的适应任务中进行的广泛实验表明,所提出的框架可以轻松实现最新性能。
SED
噪声数据是难以拟合的,可以通过计算SED来判断当前的伪标签是否具有置信度以及搜索出一个最佳的confidence threshold.
False Negatives Simulation
在实验中发现占比做多的为FN, 且表现为小目标及遮挡严重的物体,因此使用增强(马赛克增强)来将容易识别的物体转化为FN的表现形式。
项目中如果有大量未标注数据,可以在标注数据预训练好检测模型后使用SFOD在大量的未标注数据中进行无监督的域自适应训练,或者用于快速拟合相似场景的模型
Transformer
OneNet
an effective baseline for endto-end one-stage object detection
PAPER ADDRESS
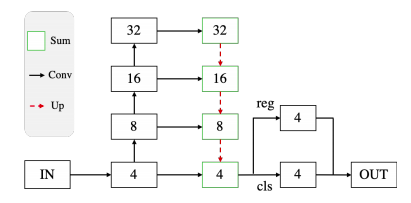
- OneNet将classification cost加入到location cost中,可以去除后续的NMS;
- 样本匹配策略是one-to-one,即一个gt一个正样本,其他都是负样本;
Backbone: Backbone是先bottom-up再top-down的结构。其中,bottom-up结构是resnet,top-down结构是FPN。
Head: Head是两个并行的conv,分类conv预测类别,回归conv预测到物体框的4个边界的距离。
Output: 直接取top-k高分框,没有NMS,也没有类似CenterNet中max-pooling的操作
Label Assignment
Label Assignment(样本选择策略)的cost定义为样本与gt的classification cost(loss)和location cost(loss)之和,即: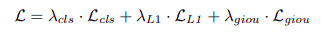
POTO
End-to-End Object Detection with Fully Convolutional Network
PAPER ADDRESS
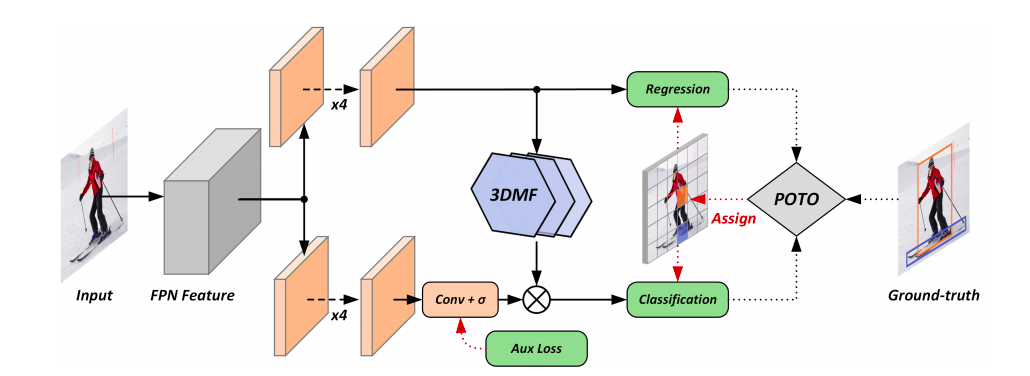
基于全卷积网络的主流目标检测器大多数仍然需要非最大抑制(NMS)后处理,在这篇文章中,我们不再使用NMS,为此,对于完全卷积检测器,我们引入了Prediction-aware One-To-One:POTO label assignment for classification,以实现端到端检测,获得与NMS相当的性能。此外,提出了一种简单的3D Max Filtering(3DMF),利用多尺度特征,提高局部区域卷积的可分辨性。
Prediction-aware One-to-one Label Assignment
使用固定的hand-designed one-to-one label assignment得到的location往往不是最优的,因此,这种强迫式地分配会使得网络收敛难度增加,同时造成更多的False-positive预测。作者这里根据Prediction的质量来进行label assignment。目标检测的损失函数为:
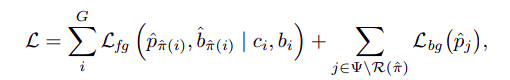
其中,$\Psi$表示所有预测的索引集(the index set of all the predictions), $N$ 和 $G$分别表示Prediction bounding boxes的数量,Ground Truth bounding boxes 的数量, $L_{fg}$表示前景损失,$L_{bg}$表示背景损失。$c_{i}$, $b_{i}$分别是Ground Truth的类别标签以及回归坐标,与之对应着的$\hat{p}{\hat{\pi}(i)}$和$\hat{b}{\hat{\pi}(i)}$是预测类别分数以及预测的bounding boxes坐标。
作者这里选取label assignment的指标为:
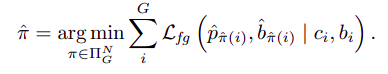
前人的工作中通过使用foreground loss将其看成是一个biparticle matching problem(二分匹配问题),使用Hungarian algorithm求解,但是foreground loss通常需要额外的权重来减轻优化问题
这里,作者采用的方式是(POTO)来获得一个更好的assignment
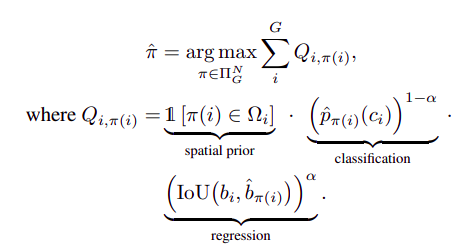
其中,$Q_{i, \pi(i)} \in [0,1]$表示第i个Ground-Truth 和我们选择的作为第i个label assignment $\pi(i)$之间的匹配质量。其中考虑了空间先验,分类的置信度以及回归的质量。$\Omega_{i}$表示第i个地面真值的候选预测集,即空间先验,同时对classification和regression利用$\alpha$进行了加权几何平均数
- 3D Max Filtering
作者发现重复预测主要来自最可靠预测的邻近空间区域
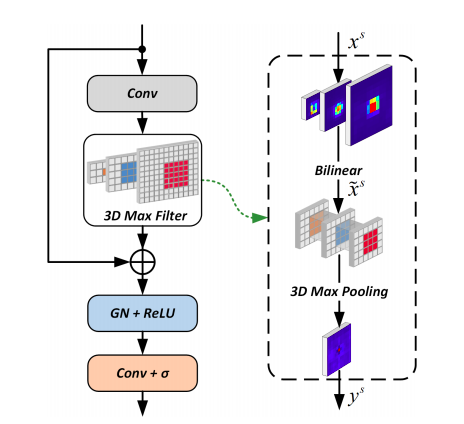
3D Max Filtering能够变换FPN多个尺度的特征,特征图中的每一个通道分别采用3D最大值滤波。
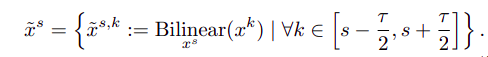
- Auxiliary Loss
使用了POTO以及3DMF得到的表现性能依旧不如FCOS baseline,这种现象可能是由于一对一的标签分配提供较少的监督,使得网络难以学习强有力的特征表示造成的.作者这里引入auxiliary loss来增强学习特征表示的能力。
auxiliary loss采用Focal loss和改进的一对多标签分配,具体来说,根据之前公式(4)$Q_{i, \pi(i)} \in [0,1]$建议的匹配质量, one-to-many label assignment 首先选出前9个预测作为每个FPN阶段的候选,然后,它将候选对象指定为匹配质量超过统计阈值的前景样本,这个统计阈值是通过the summation of the mean and the standard deviation of all the candidate matching qualities来计算出来的.

从上图中可以看出,FCOS baseline有一对多的分配中心输出大量的重复预测,很多位置的置信度分数较高,这些重复的预测被评估为假阳性样本,并极大地影响性能。相反,通过使用所提出的POTO规则,重复样本的分数被显著抑制。在引入3DMF后,达到更好的效果,这是由于3DMF模块引入了多尺度竞争机制,检测器可以在不同的FPN阶段很好地执行独特的预测
One Stage
YOLO V1
You only look once unified real-time object detection
作者在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。
优点:
- YOLO的速度非常快。在Titan X GPU上的速度是45 fps, 加速版155 fps。
- YOLO是基于图像的全局信息进行预测的。这一点和基于sliding window以及region proposal等检测算法不一样。与Fast R-CNN相比,YOLO在误检测(将背景检测为物体)方面的错误率能降低一半多。
- 泛化能力强。
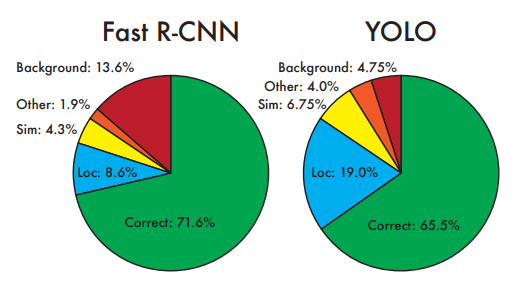
缺点:
- accuracy 还落后于同期 state-of-the-art 目标检测方法。
- 难于检测小目标。
- 定位不够精准。
- 虽然降低了背景检测为物体的概率但同事导致了召回率较低。
流程
- 调整图像大小至$448\times448$.
- 运行卷积网络同时预测多目标的边界框和所属类的概率
- NMX(非极大值抑制)
Unified Detection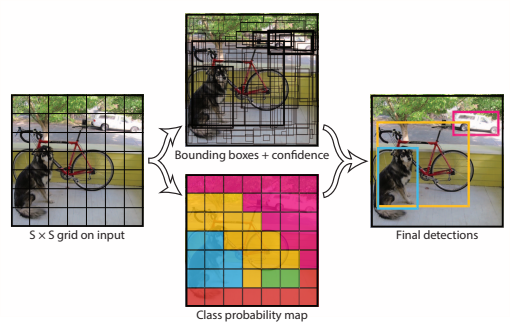
- 将图片分为$S\times S$格子。
- 对每个格子都预测B个边界框并且每个边界框包含5个预测值:x,t,w,h以及confidence。x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;w和h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围。
- 每个格子都预测C个假定类别的概率。
- 在Pascal VOC中, S=7,B=2,C=20. 所以有 $S\times S\times (B \times 5 + C)$ 即 $7\times 7\times 30$ 维张量。
Confidence计算:$Pr(Object) * IOU_{pred}^{turth} $
每个bounding box都对应一个confidence score,如果grid cell里面没有object,confidence就是0,如果有,则confidence score等于预测的box和ground truth的IOU值,见上面公式。并且如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
每个grid cell都预测C个类别概率,表示一个grid cell在包含object的条件下属于某个类别的概率:$Pr(Class_{i}|Object)$
每个bounding box的confidence和每个类别的score相乘,得到每个bounding box属于哪一类的confidence score。
即得到每个bounding box属于哪一类的confidence score。也就是说最后会得到20*(7*7*2)的score矩阵,括号里面是bounding box的数量,20代表类别。接下来的操作都是20个类别轮流进行:在某个类别中(即矩阵的某一行),将得分少于阈值(0.2)的设置为0,然后再按得分从高到低排序。最后再用NMS算法去掉重复率较大的bounding box(NMS:针对某一类别,选择得分最大的bounding box,然后计算它和其它bounding box的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,再选择剩下的score里面最大的那个bounding box,然后计算该bounding box和其它bounding box的IOU,重复以上过程直到最后)。最后每个bounding box的20个score取最大的score,如果这个score大于0,那么这个bounding box就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bounding box里面没有物体,跳过即可。
网络设计
灵感来源于GoogLeNet,如下图: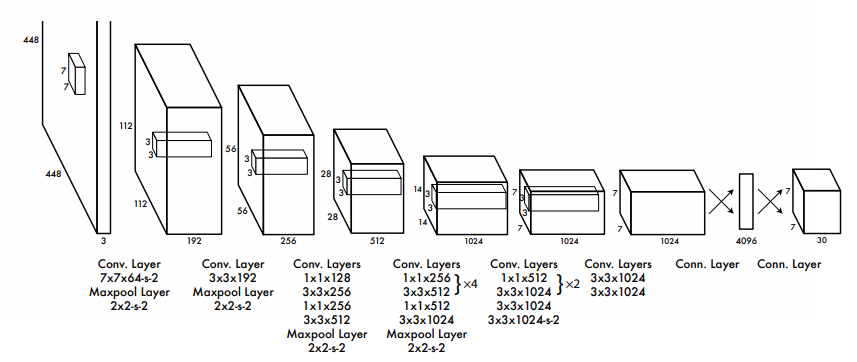
训练过程中:
- 作者先在ImageNet数据集上预训练网络,而且网络只采用图中的前面20个卷积层,输入是224*224大小的图像。然后在检测的时候再加上随机初始化的4个卷积层和2个全连接层,同时输入改为更高分辨率的448*448。
- Relu层改为leaky Relu,即当x<0时,激活值是0.1*x,而不是传统的0。
- 作者采用sum-squared error的方式把localization error(bounding box的坐标误差)和classificaton error整合在一起。但是如果二者的权值一致,容易导致模型不稳定,训练发散。因为很多grid cell是不包含物体的,这样的话很多grid cell的confidence score为0。所以采用设置不同权重方式来解决,一方面提高localization error的权重,另一方面降低没有object的box的confidence loss权值,loss权重分别是5和0.5。而对于包含object的box的confidence loss权值还是原来的1。
- 用宽和高的开根号代替原来的宽和高,这样做主要是因为相同的宽和高误差对于小的目标精度影响比大的目标要大.
- Loss Function如下:
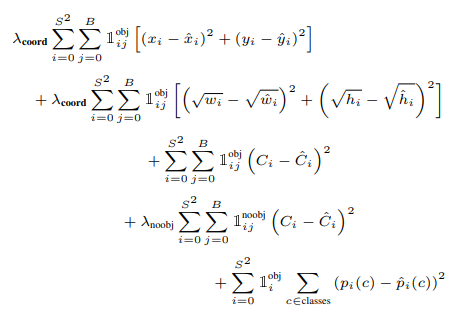
训练的时候:输入N个图像,每个图像包含M个objec,每个object包含4个坐标(x,y,w,h)和1个label。然后通过网络得到7*7*30大小的三维矩阵。每个1*30的向量前5个元素表示第一个bounding box的4个坐标和1个confidence,第6到10元素表示第二个bounding box的4个坐标和1个confidence。最后20个表示这个grid cell所属类别。注意这30个都是预测的结果。然后就可以计算损失函数的第一、二 、五行。至于第二三行,confidence可以根据ground truth和预测的bounding box计算出的IOU和是否有object的0,1值相乘得到。真实的confidence是0或1值,即有object则为1,没有object则为0。 这样就能计算出loss function的值了。
测试的时候:输入一张图像,跑到网络的末端得到7*7*30的三维矩阵,这里虽然没有计算IOU,但是由训练好的权重已经直接计算出了bounding box的confidence。然后再跟预测的类别概率相乘就得到每个bounding box属于哪一类的概率。
YOLO效果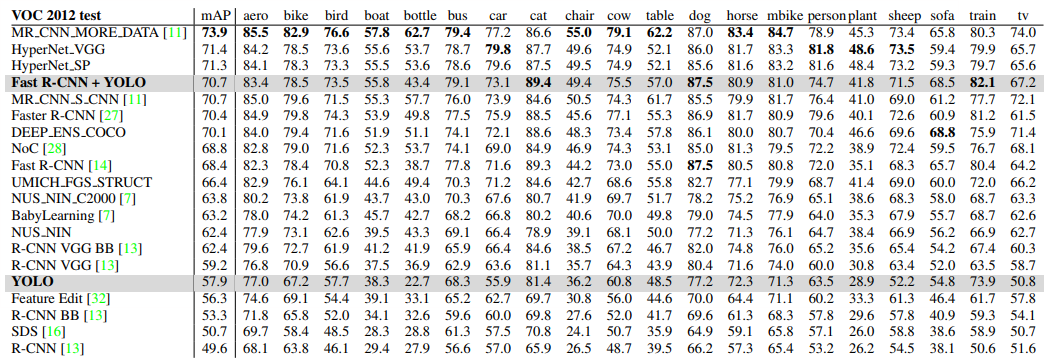
由于yolo更少的识别背景为物体对比Faster RCNN,因此结合YOLO作为背景检测器与Faster RCNN可以带来更大的提升,不过速度方面就没有优势了。
YOLO V2 and YOLO 9000
与分类和标记等其他任务的数据集相比,目前目标检测数据集是有限的。最常见的检测数据集包含成千上万到数十万张具有成百上千个标签的图像。分类数据集有数以百万计的图像,数十或数十万个类别。为了扩大当前检测系统的范围。我们的方法使用目标分类的分层视图,允许我们将不同的数据集组合在一起。此外联合训练算法,使我们能够在检测和分类数据上训练目标检测器。我们的方法利用标记的检测图像来学习精确定位物体,同时使用分类图像来增加词表和鲁棒性。
对比YOLO V1的改进
- YOLO有许多缺点。YOLO与Fast R-CNN相比的误差分析表明,YOLO造成了大量的定位误差。此外,与基于区域提出的方法相比,YOLO召回率相对较低。因此,我们主要侧重于提高召回率和改进定位,同时保持分类准确性。
在YOLOv2中,一个更精确的检测器被设计出来,它仍然很快。但是不是通过扩大网络,而是简化网络,然后让其更容易学习。结合了以往的一些新方法,以提高YOLO的性能:
- Batch Normalization: map提升2%
- High Resolution Classifier: 先在ImageNet上以448×448的分辨率对分类网络进行10个迭代周期的微调。这给了网络时间来调整其滤波器以便更好地处理更高分辨率的输入。map提升4%,
- Convolutional With Anchor Boxes: 从YOLO中移除全连接层,并使用锚盒来预测边界框。首先,我们消除了一个池化层,使网络卷积层输出具有更高的分辨率。我们还缩小了网络,操作416×416的输入图像而不是448×448。我们这样做是因为我们要在我们的特征映射中有奇数个位置,所以只有一个中心单元。目标,特别是大目标,往往占据图像的中心,所以在中心有一个单独的位置来预测这些目标,而不是四个都在附近的位置是很好的。YOLO的卷积层将图像下采样32倍,所以通过使用416的输入图像,我们得到了13×13的输出特征映射。map有所下降但是召回率达到了88%.
- Dimension Clusters: Anchors 尺寸的选择用k-means聚类来挑选合适的锚盒尺寸。如果我们使用具有欧几里得距离的标准k-means,那么较大的边界框比较小的边界框产生更多的误差。然而,我们真正想要的是导致好的IOU分数的先验,这是独立于边界框大小的。因此,对于我们的距离度量,我们使用:$d(box,centroid)=1-IOU(box,centroid)$. 在voc和coco的测试中,更薄更高的边界框会带来更好的结果在k=5的时候,如图所示:
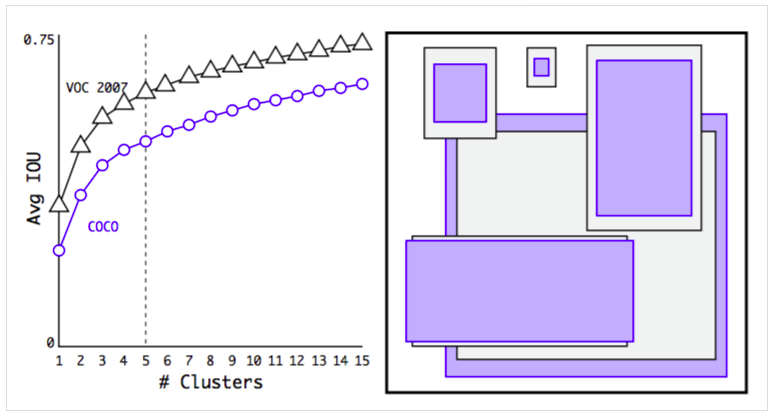
- Direct location prediction: 传统的RPN中,特别是在早期的迭代过程中。大部分的不稳定来自预测边界框的(x,y)位置,他的位置修正方法是不受限制的,所以任何锚盒都可以在图像任一点结束,而不管在哪个位置预测该边界框。随机初始化模型需要很长时间才能稳定以预测合理的偏移量。所以这一步就优化为直接预测相对于网格单元位置的位置坐标。逻辑激活备用来限制网络的预测落在这个范围内。Sigmoid使输出在0~1之间这样映射到原图中时候不会位于其他的网格(在中心目标处)。
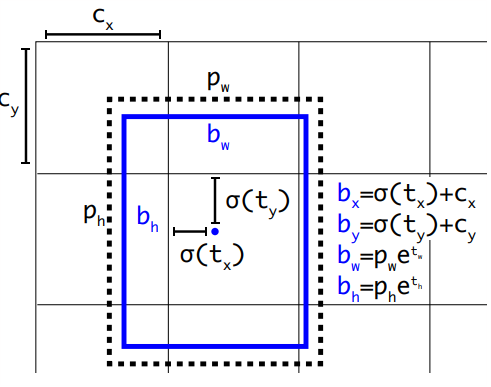 网络预测输出特征映射中每个单元的5个边界框。网络预测每个边界框的5个坐标,$t_{x}$,$t_{y}$,$t_{w}$,$t_{h}$,$t_{o}$,如果单元从图像的左上角偏移了$(c_{x},c_{y})$,并且边界框先验的宽度和高度为$p_{w}$,$p_{h}$. 预测就可以对应如图公式计算。$Pr(object)\times IOU(b,object)=\sigma(t_{o}) $ 该方法结合维度聚类,map 提升了5%对比与其他的锚盒方法。
网络预测输出特征映射中每个单元的5个边界框。网络预测每个边界框的5个坐标,$t_{x}$,$t_{y}$,$t_{w}$,$t_{h}$,$t_{o}$,如果单元从图像的左上角偏移了$(c_{x},c_{y})$,并且边界框先验的宽度和高度为$p_{w}$,$p_{h}$. 预测就可以对应如图公式计算。$Pr(object)\times IOU(b,object)=\sigma(t_{o}) $ 该方法结合维度聚类,map 提升了5%对比与其他的锚盒方法。 - Fine-Grained Features(细粒度特征): 对于小目标物体,更细的力度特种可以带来更好的效果,因此直通层通过将相邻特征堆叠到不同的通道而不是空间位置来连接较高分辨率特征和较低分辨率特征,类似于ResNet中的恒等映射。这将26×26×512特征映射变成13×13×2048特征映射,其可以与原始特征连接。我们的检测器运行在这个扩展的特征映射的顶部,以便它可以访问细粒度的特征。这会使性能提高1%。
- Multi-Scale Training: 由于模型只使用卷积层和池化层,因此它可以实时调整大小。所以每隔10个批次会随机选择一个新的图像尺寸大小(330到608,从32的倍数中选择因为模型缩减了32倍),强迫网络学习在不同维度上预测,并且小尺度的网络运行更快。
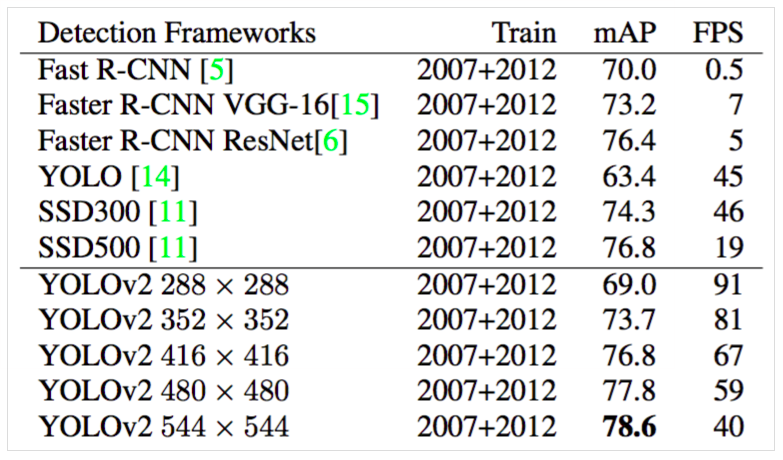
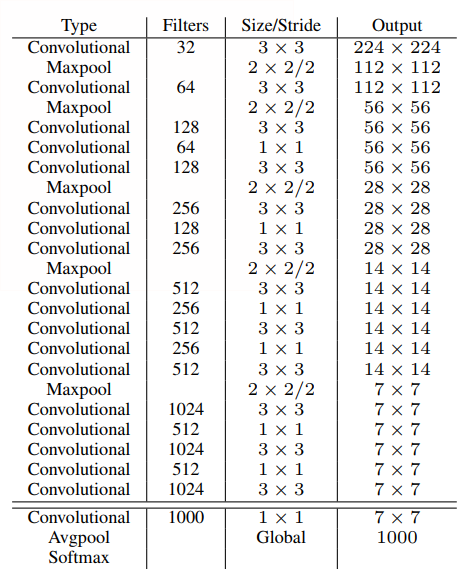
Darknet-19, 它有19个卷积层和5个最大池化层并且只需要55.8亿次运算处理图像获得了比复杂运算VGG和前一代YOLO更高的top-5精度在ImageNet上,结构如下:
- 分类训练:使用Darknet神经网络结构,使用随机梯度下降,初始学习率为0.1,学习率多项式衰减系数为4,权重衰减为0.0005,动量为0.9,在标准ImageNet 1000类分类数据集上训练网络160个迭代周期。在训练过程中,标准的数据增强技巧,包括随机裁剪,旋转,色调,饱和度和曝光偏移被使用来防止over-fitting. 在在对224×224的图像进行初始训练之后,对网络在更大的尺寸448上进行了微调。
- 检测训练:删除了最后一个卷积层,加上了三个具有1024个滤波器的3×3卷积层,其后是最后的1×1卷积层与我们检测需要的输出数量。对于VOC,我们预测5个边界框,每个边界框有5个坐标和20个类别,所以有125个滤波器。还添加了从最后的3×3×512层到倒数第二层卷积层的直通层,以便模型可以使用细粒度特征。
- 联合训练分类和检测数据:
- 网络看到标记为检测的图像时,可以基于完整的YOLOv2损失函数进行反向传播。当它看到一个分类图像时,只能从该架构的分类特定部分反向传播损失。
- Hierarchical classification(分层分类):ImageNet标签是从WordNet中提取的,这是一个构建概念及其相互关系的语言数据库,在这里通过构建简单的分层树简化问题。最终的结果是WordTree,一个视觉概念的分层模型。为了使用WordTree进行分类,我们预测每个节点的条件概率,以得到同义词集合中每个同义词下义词的概率。如果想要计算一个特定节点的绝对概率,只需沿着通过树到达根节点的路径,再乘以条件概率。可以使用WordTree以合理的方式将多个数据集组合在一起。只需将数据集中的类别映射到树中的synsets即可。
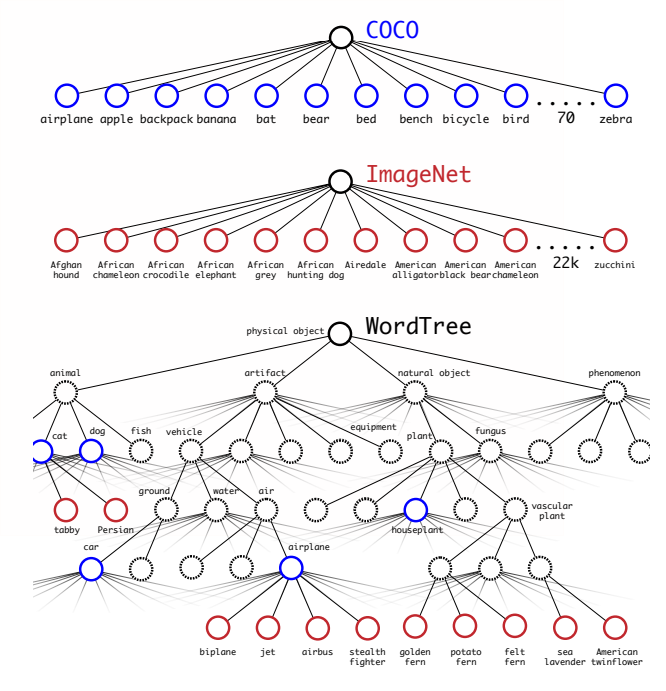
- YOLO 9000(anchors尺寸3个限制输出大小): 使用COCO检测数据集和完整的ImageNet版本中的前9000个类来创建的组合数据集。该数据集的相应WordTree有9418个类别。ImageNet是一个更大的数据集,所以通过对COCO进行过采样来平衡数据集,使得ImageNet仅仅大于4:1的比例。当分析YOLO9000在ImageNet上的表现时,发现它很好地学习了新的动物种类,但是却在像服装和设备这样的学习类别中挣扎。新动物更容易学习,因为目标预测可以从COCO中的动物泛化的很好。相反,COCO没有任何类型的衣服的边界框标签,只针对人,因此效果不好3
YOLO V3
论文地址
模型: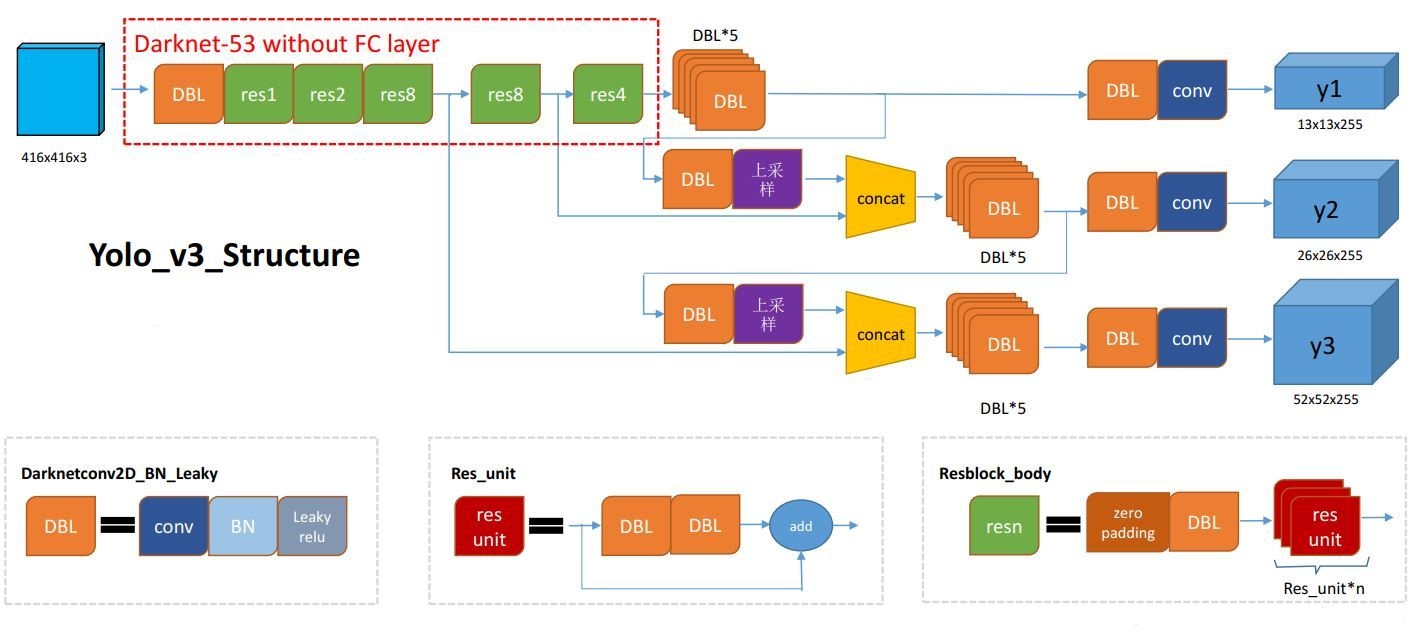
改进:
- 将YOLO V3替换了V2中的Softmax loss变成Logistic loss(每个类一个logistic),而且每个GT只匹配一个先验框.
- Anchor bbox prior不同:V2用了5个anchor,V3用了9个anchor,提高了IOU.
- Detection的策略不同:V2只有一个detection,V3设置有3个,分别是一个下采样的,Feature map为13*13,还有2个上采样的eltwise sum(feature pyramid networks),Feature map分别为26\26和52\52,也就是说,V3的416版本已经用到了52的Feature map,而V2把多尺度考虑到训练的data采样上,最后也只是用到了13的Feature map,这应该是对小目标影响最大的地方。
总结:
- 网络改进 DarkNet-53: 融合了YOLOv2、Darknet-19以及其他新型残差网络,由连续的3×3和1×1卷积层组合而成,当然,其中也添加了一些shortcut connection,整体体量也更大。因为一共有53个卷积层。
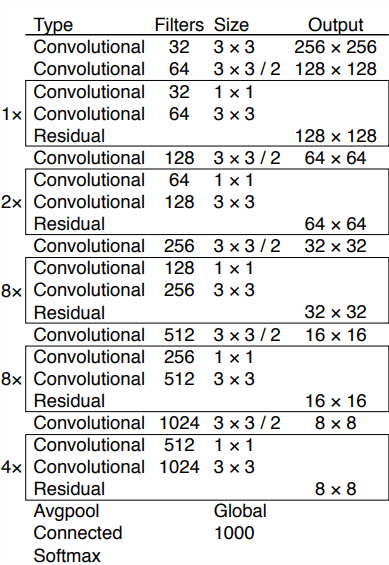
- LOSS: 除了w, h的损失函数依然采用总方误差之外,其他部分的损失函数用的是二值交叉熵。最后加到一起
1
2
3
4
5
6
7
8
9
10xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + (1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
结果:
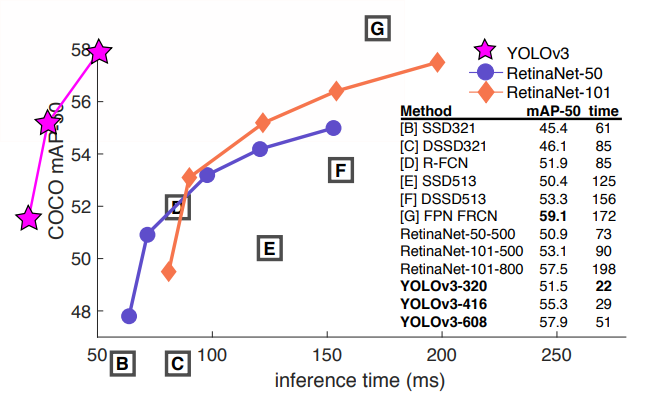
- YOLO V3在Pascal Titan X上处理608x608图像速度达到20FPS,在 COCO test-dev 上 mAP@0.5 达到 57.9%,与RetinaNet的结果相近,并且速度快了4倍。 YOLO V3的模型比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。 速度对比如下:
- 失败的尝试:
- Anchor box坐标的偏移预测
- 用线性方法预测x,y,而不是使用逻辑方法
- focal loss
- 双IOU阈值和真值分配
YOLO V4
论文地址
模型: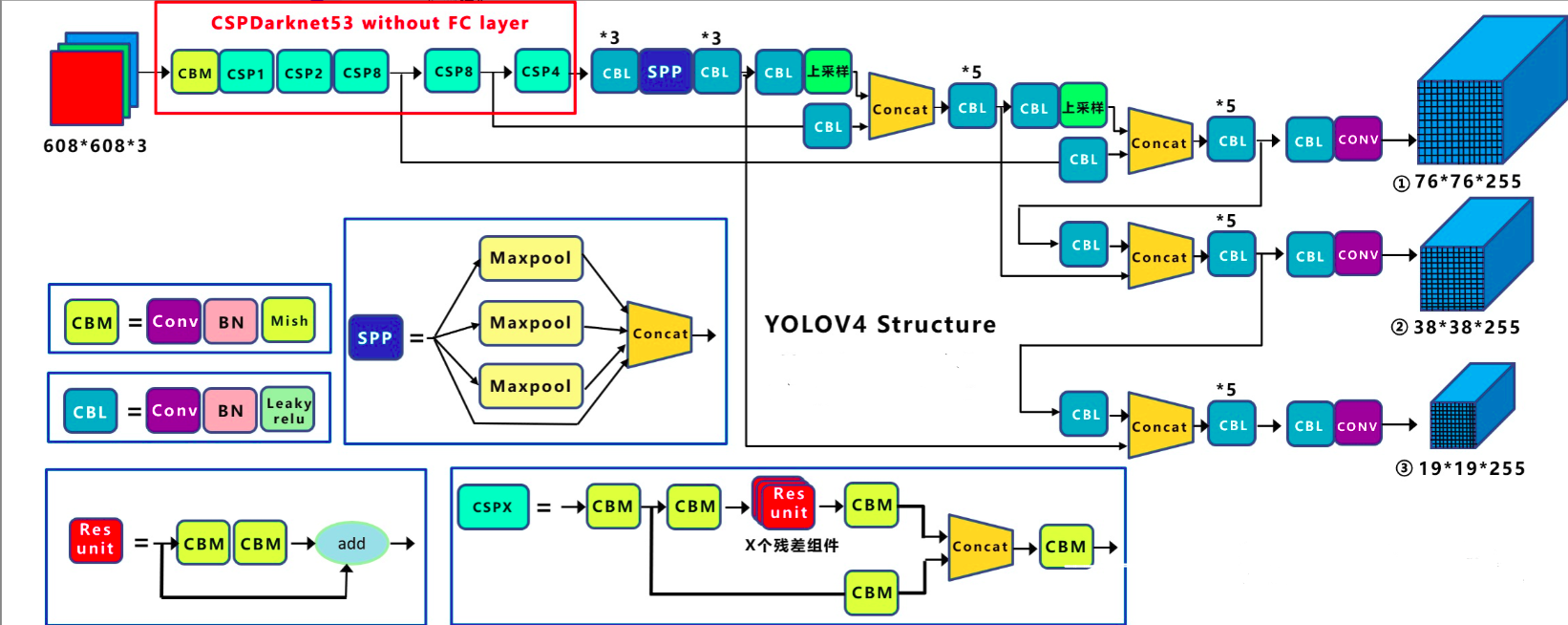
- CBM: Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
- CBL: 由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit: 借鉴Resnet网络中的残差结构,让网络可以构建的更深。
- CSPX: 借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
- SPP: 采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
每个CSPX中包含3+2X个卷积层,因此整个主干网络Backbone中一共包含$2+(3+21)+2+(3+22)+2+(3+28)+2+(3+28)+2+(3+24)+1=72$。
评估过的技术
改进:
- 输入端: Mosaic数据增强、cmBN、SAT自对抗训练、类别标签平滑化
- Backbone: CSPDarknet53、Mish激活函数、Dropblock
- Nect: SPP模块、PAN结构
- Prediction: CmBN、最优超参数、CIOU_Loss,DIOU_nms
mosaic:
pro:
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
CSPNet:
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。
因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点:
- 增强CNN的学习能力,使得在轻量化的同时保持准确性。
- 降低计算瓶颈
- 降低内存成本
Mish: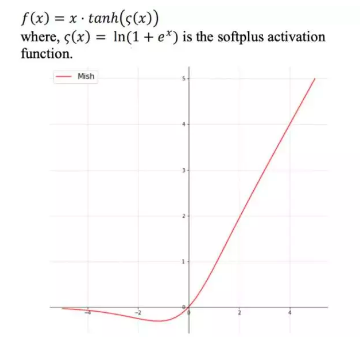
正值可以达到任何高度, 避免了由于封顶而导致的饱和。理论上对负值的轻微允许更好的梯度流,而不是像ReLU中那样的硬零边界。
Dropblock: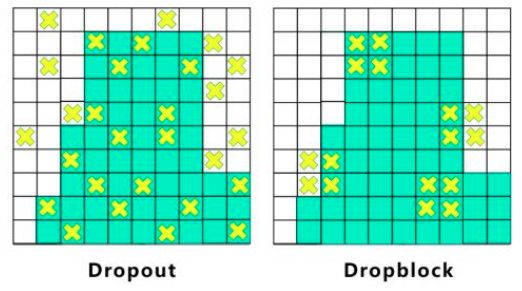
卷积层对于dropout丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。
SPP:
采用SPP模块的方式,比单纯的使用k*k最大池化的方式,更有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征。
在SPP模块中,使用k=[1x1, 5x5, 9x9, 13x13]的最大池化的方式,再将不同尺度的特征图进行Concat操作。
PAN:
PAN模型也叫金字塔注意力模型,主要由FPA(特征金字塔注意力模块)和GAU两个模型组成
- FPA
该模块能够融合来自 U 型网络 (如特征金字塔网络 FPN) 所提取的三种不同尺度的金字塔特征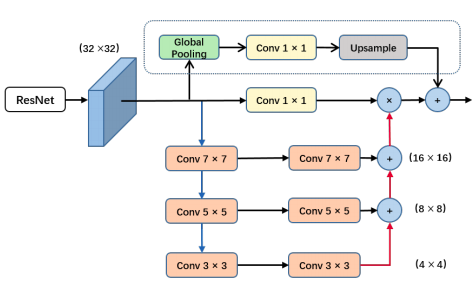
- GAU
GAU是用在decode时候的单元,并且引入注意力机制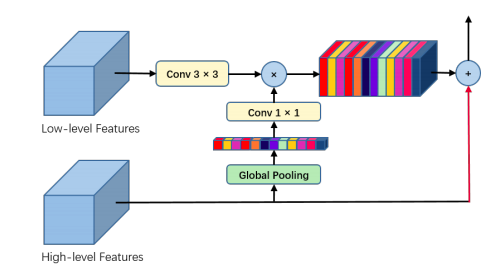
yolov4包含两个PAN结构,并且只取最后一个特征图,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。
IOU LOSS:
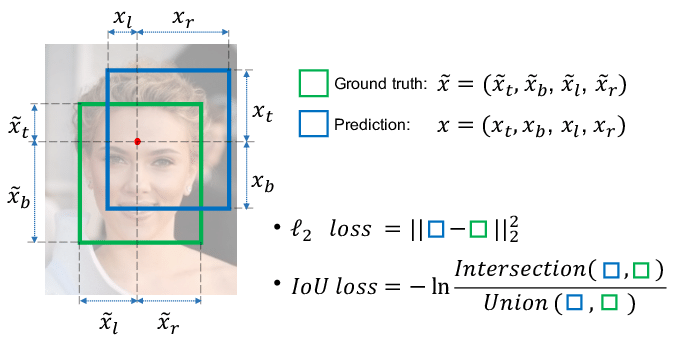
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
pro:
- IoU损失将位置信息作为一个整体进行训练, 对比L2损失对4个独立变量进行训练能得到更为准确的效果.
con:
- 当预测框和目标框不相交时,IoU(A,B)=0时,不能反映A,B距离的远近,此时损失函数不可导,IoU Loss 无法优化两个框不相交的情况。
- 假设预测框和目标框的大小都确定,只要两个框的相交值是确定的,其IoU值是相同时,IoU值不能反映两个框是如何相交的。
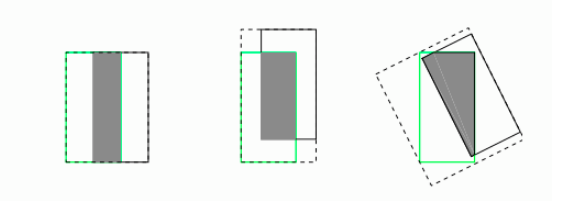
- GIOU loss

找到一个最小的外接矩形C,让C可以将A和B包围在里面,然后我们计算C中没有覆盖A和B的面积占C总面积的比例,然后用A和B的IOU值减去这个比值
pro:
- 预测框和目标不相交的情况下也可以进行优化,且对物体的尺度大小不敏感(因为比值的原因)
con:
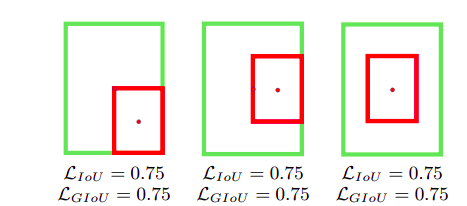
- 当目标框完全包裹预测框的时候,IoU和GIoU的值都一样,此时GIoU退化为IoU, 无法区分其相对位置关系
- DIOU loss
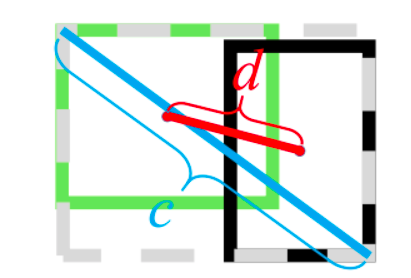
通常基于IoU-based的loss可以定义为$L=1-IOU+R(B,B^{gt})$其中$R(B,B^{gt})$)定义为预测框$B$和目标框$B^{gt}$的惩罚项。
$DIoU=IoU - \frac{p^{2}(b,b^{gt})}{c^{2}}$
其中,$b$和$b^{gt}$分别代表了预测框和真实框的中心点,且代表的是计算两个中心点间的欧式距离。$c$代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
pro:
- 即使目标框完全包裹预测框的时候也可以进行优化
- 将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题
- DIoU还可以替换普通的IoU评价策略,应用于NMS中,使得NMS得到的结果更加合理和有效。
con:
- 没有考虑预测框的长宽比,当预测框与目标框中心点距离相同时无法进行优化
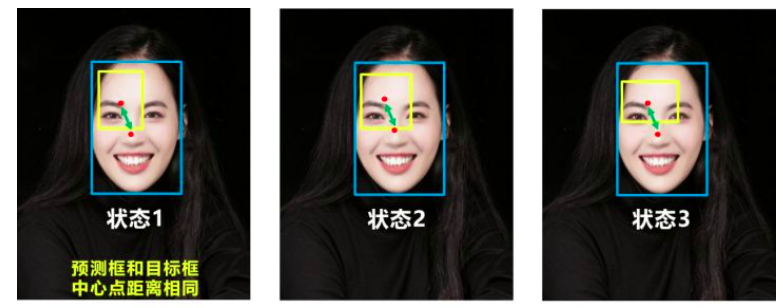
- CIOU loss
$CIoU=IoU - \frac{p^{2}(b,b^{gt})}{c^{2}} - \alpha v$
$v=\frac{4}{\pi^{2}(arctan(w^{gt}/h^{gt})-arctan(w/h))^{2}}$
$\alpha = v / ((1-IoU)+v)$
其中,$\alpha$是用于做trade-off的权重函数,$v$是用来衡量长宽比一致性的参数
pro:
- 目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了
结果: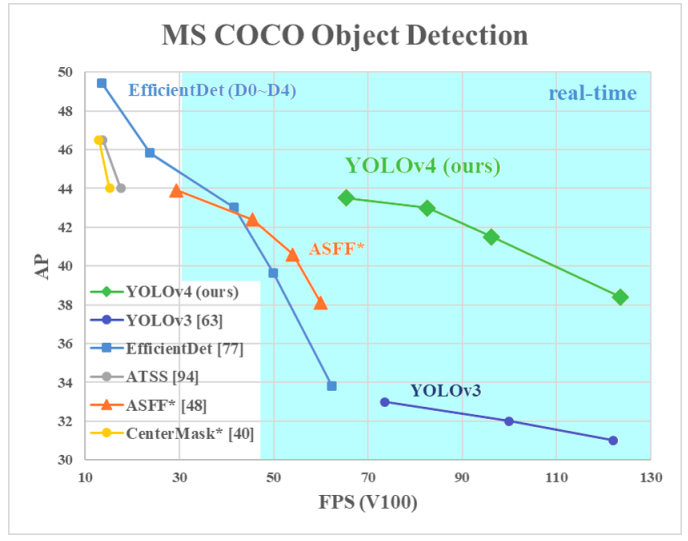
YOLO V5
代码地址
模型: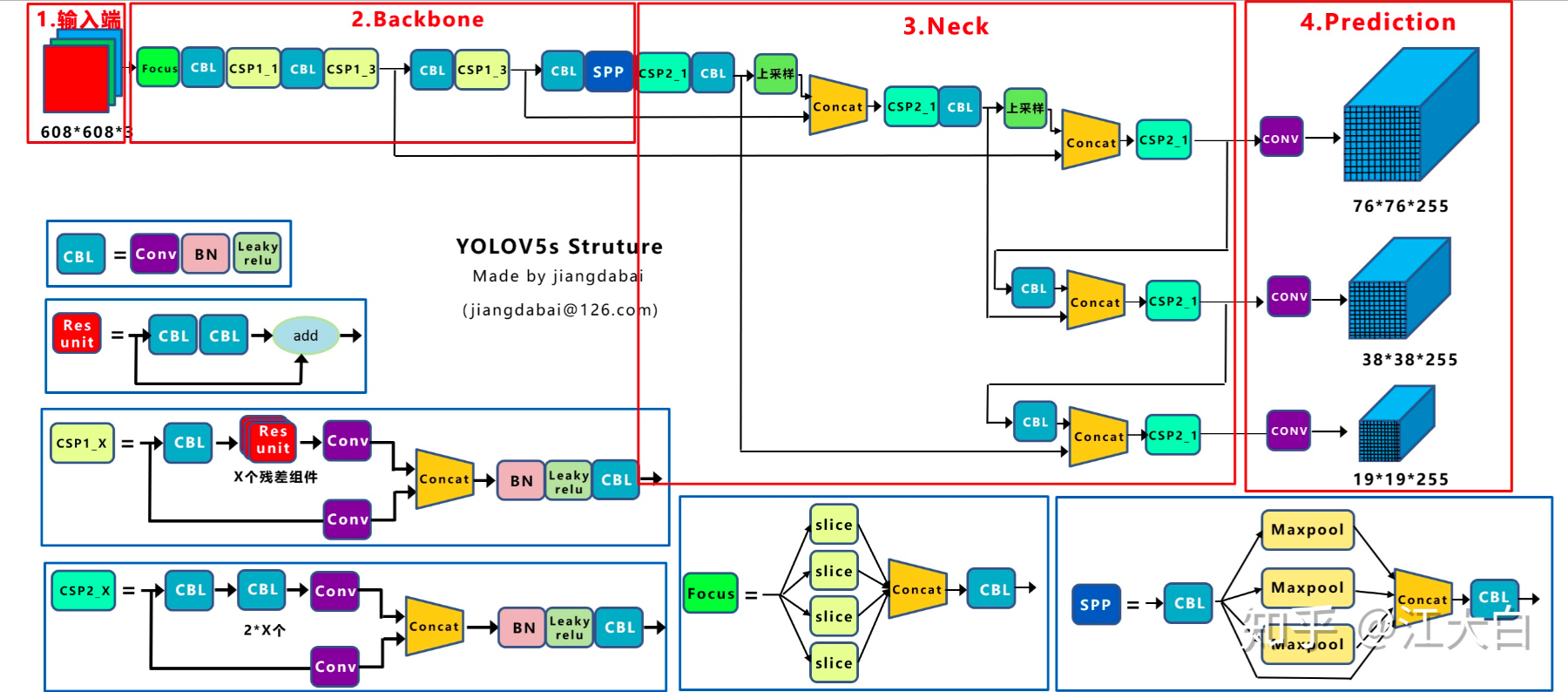
Backbone
Focus结构
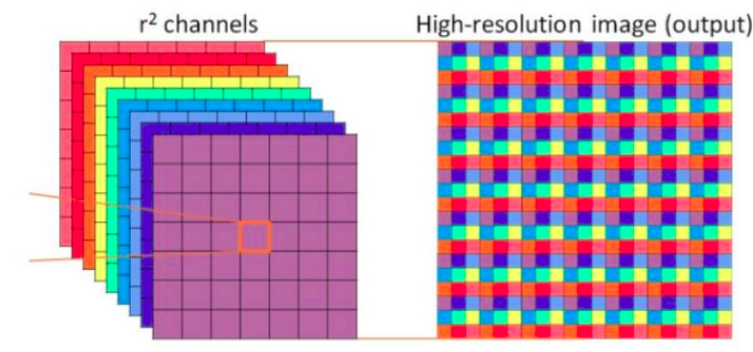
这个其实就是yolov2里面的ReOrg+Conv操作,也是亚像素卷积的反向操作版本,简单来说就是把数据切分为4份,每份数据都是相当于2倍下采样得到的,然后在channel维度进行拼接,最后进行卷积操作。以Yolov5s的结构为例,原始$6086083$的图像输入Focus结构,采用切片操作,先变成$30430412$的特征图,再经过一次32个卷积核的卷积操作,最终变成$30430432$的特征图CSP结构
Yolov5与Yolov4不同点在于,Yolov4中只有主干网络使用了CSP结构。而Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。Neck结构
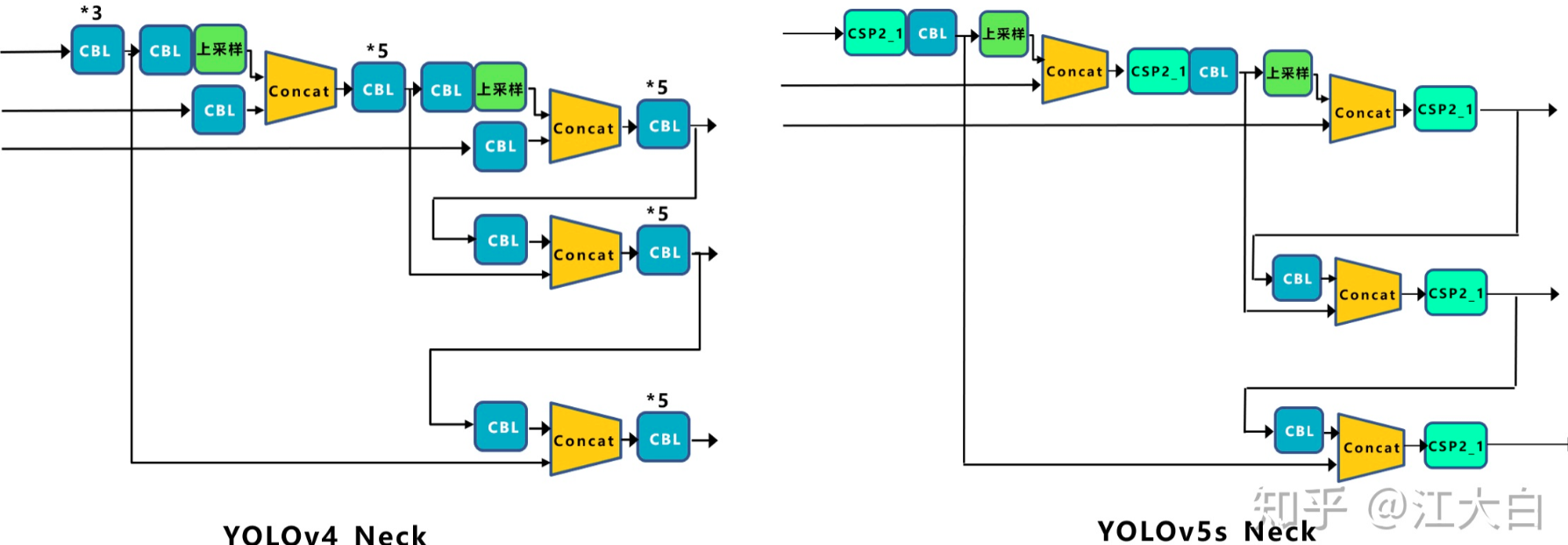
Yolov5和Yolov4的不同点在于,Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
结构参数
yolov5通过灵活的配置参数,可以得到不同复杂度的模型Yolov5s
depth_multiple: 0.33
width_multiple: 0.50Yolov5m
depth_multiple: 0.67
width_multiple: 0.75Yolov5l
depth_multiple: 1.0
width_multiple: 1.0Yolov5x
depth_multiple: 1.33
width_multiple: 1.25
Anchor匹配策略
在诸多论文研究中表明,例如FCOS和ATSS:增加高质量正样本anchor可以显著加速收敛。
yolov5也采用了增加正样本anchor数目的做法来加速收敛,这其实也是yolov5在实践中表明收敛速度非常快的原因。其核心匹配规则为:
对于任何一个输出层,抛弃了基于max iou匹配的规则,而是直接采用shape规则匹配,也就是该bbox和当前层的anchor计算宽高比,如果宽高比例大于设定阈值,则说明该bbox和anchor匹配度不够,将该bbox过滤暂时丢掉,在该层预测中认为是背景
对于剩下的bbox,计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该bbox的,可以发现粗略估计正样本数相比前yolo系列,至少增加了三倍
因此不同于yolov3和v4,
- 其gt bbox可以跨层预测即有些bbox在多个预测层都算正样本
- 其gt bbox的匹配数范围从3-9个,明显增加了很多正样本
- *有些gt bbox由于和anchor匹配度不高,而变成背景
虽然可以加速收敛,但是由于引入了很多低质量anchor,对最终结果还是有影响的
- 自适应anchor计算
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
结果: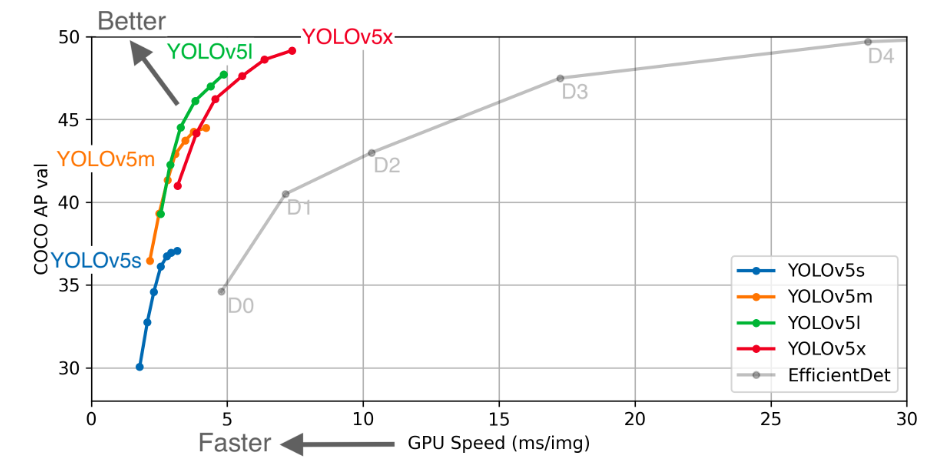
SSD: Single Shot MultiBox Detector
SSD将边界框的输出空间离散化为不同长宽比的一组默认框和并缩放每个特征映射的位置。在预测时,网络会在每个默认框中为每个目标类别的出现生成分数,并对框进行调整以更好地匹配目标形状。此外,网络还结合了不同分辨率的多个特征映射的预测,自然地处理各种尺寸的目标。
改进:
- 针对多个类别的单次检测器
- 预测固定的一系列默认边界框的类别分数和边界框偏移,使用更小的卷积滤波器应用到特征映射上
- 根据不同尺度的特征映射生成不同尺度的预测,并通过纵横比明确分开预测
- 在低分辨率输入图像上也能实现简单的端到端训练和高精度,从而进一步提高速度与精度之间的权衡。
模型: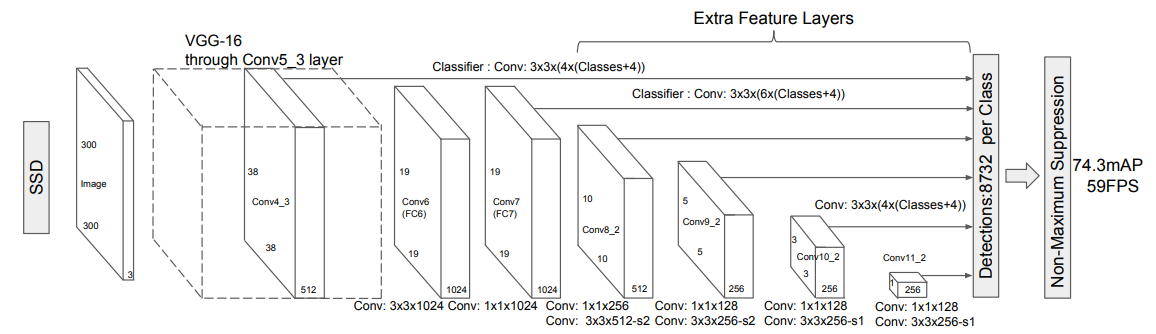
SSD方法基于前馈卷积网络,该网络产生固定大小的边界框集合,并对这些边界框中存在的目标类别实例进行评分,然后进行非极大值抑制步骤来产生最终的检测结果。早期的网络层基于用于高质量图像分类的标准架构将其称为基础网络。然后,将辅助结构添加到网络中以产生具有以下关键特征的检测:
- 用于检测的多尺度特征映射。我们将卷积特征层添加到截取的基础网络的末端。这些层在尺寸上逐渐减小,并允许在多个尺度上对检测结果进行预测。用于预测检测的卷积模型对于每个特征层都是不同的
- 用于检测的卷积预测器。每个添加的特征层(或者任选的来自基础网络的现有特征层)可以使用一组卷积滤波器产生固定的检测预测集合。
- 默认边界框和长宽比。默认边界框与Faster R-CNN[2]中使用的锚边界框相似,但是我们将它们应用到不同分辨率的几个特征映射上。在几个特征映射中允许不同的默认边界框形状可以有效地离散可能的输出框形状的空间。
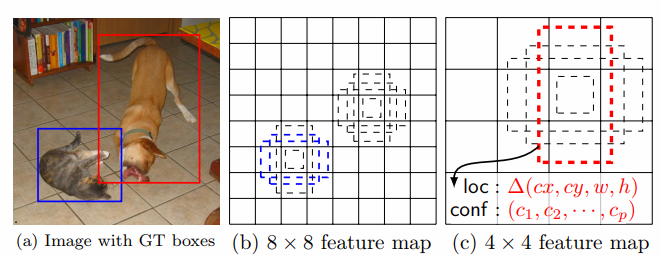
- 总结: 末尾添加的特征层预测不同尺度的长宽比的默认边界框的偏移量以及相关的置信度。PS: 空洞版本VGG更快。
训练:
- 匹配策略:默认边界框匹配到IOU重叠高于阈值(0.5)的任何实际边界框。这简化了学习问题,允许网络为多个重叠的默认边界框预测高分,而不是要求它只挑选具有最大重叠的一个边界框。
- 训练目标函数:定位损失加上置信度损失

- 为默认边界框选择尺度和长宽比:

- 难例挖掘: 在匹配步骤之后,大多数默认边界框为负例,尤其是当可能的默认边界框数量较多时。这在正的训练实例和负的训练实例之间引入了显著的不平衡。不使用所有负例,而是使用每个默认边界框的最高置信度损失来排序它们,并挑选最高的置信度,以便负例和正例之间的比例至多为3:1。
- 数据增强

- 小目标数据增强: 将图像随机放置在填充了平均值的原始图像大小为16x的画布上,然后再进行任意的随机裁剪操作。因为通过引入这个新的“扩展”数据增强技巧,有更多的训练图像,所以必须将训练迭代次数加倍。
优劣:
SSD对类似的目标类别(特别是对于动物)有更多的混淆,部分原因是共享多个类别的位置。SSD对边界框大小非常敏感。换句话说,它在较小目标上比在较大目标上的性能要差得多。这并不奇怪,因为这些小目标甚至可能在顶层没有任何信息。增加输入尺寸(例如从300×300到512×512)可以帮助改进检测小目标,但仍然有很大的改进空间。积极的一面,SSD在大型目标上的表现非常好。而且对于不同长宽比的目标,它是非常鲁棒的,因为使用每个特征映射位置的各种长宽比的默认框。
RetinaNet Focal Loss for Dense Object Detection
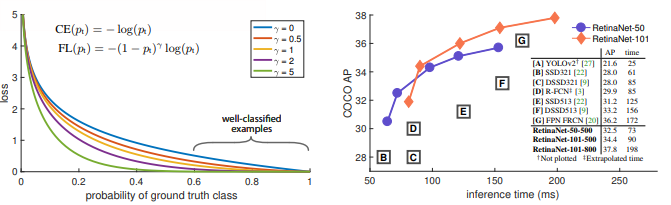
稠密分类的后者精度不够高,核心问题(central issus)是稠密proposal中前景和背景的极度不平衡。以我更熟悉的YOLO举例子,比如在PASCAL VOC数据集中,每张图片上标注的目标可能也就几个。但是YOLO V2最后一层的输出是13×13×5,也就是845个候选目标!大量(简单易区分)的负样本在loss中占据了很大比重,使得有用的loss不能回传回来。基于此,作者将经典的交叉熵损失做了变形(见下),给那些易于被分类的简单例子小的权重,给不易区分的难例更大的权重。同时,作者提出了一个新的one-stage的检测器RetinaNet,达到了速度和精度很好地trade-off。
$FL(p_{t}=-(1-p_{t})^{\gamma}log(p_{t})$
Focal Loss
Focal Loss从交叉熵损失而来。二分类的交叉熵损失如下: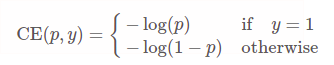
对应的,多分类的交叉熵损失是这样的:
$CE(p,y)=-log(p_{y})$
因此可以使用添加权重的交叉熵损失:
$CE(p)=-\alpha_{t}log(p_{t})$
而作者提出的是一个自适应调节的权重:(可加入权重$\alpha$平衡)
$FL(p_{t}=-(1-p_{t})^{\gamma}log(p_{t})$
Pytorch实现:
$L=-\sum_{i}^{C}onehot\odot(1-p_{t})^{\gamma}log(p_{t})$
1 | import torch |
模型:
- 模型初始化: 对于一般的分类网络,初始化之后,往往其输出的预测结果是均等的(随机猜测)。然而作者认为,这种初始化方式在类别极度不均衡的时候是有害的。作者提出,应该初始化模型参数,使得初始化之后,模型输出稀有类别的概率变小(如0.01),作者发现这种初始化方法对于交叉熵损失和Focal Loss的性能提升都有帮助。首先,从imagenet预训练得到的base net不做调整,新加入的卷积层权重均初始化为$\sigma$=0.01的高斯分布,偏置项为0.对于分类网络的最后一个卷积层,偏置项为$b=-log(\frac{(1-\pi)}{\pi})$, $\pi$是一个超参数,其意义是在训练的初始阶段,每个anchor被分类为前景的概率。
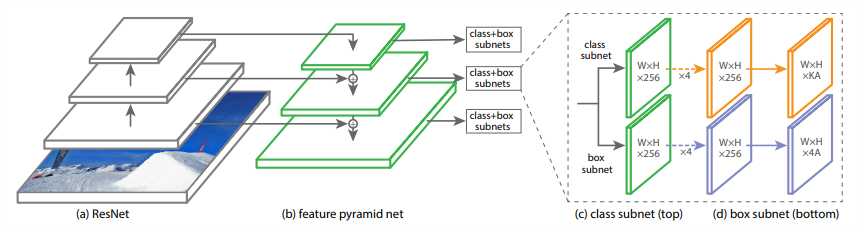
作者利用前面介绍的发现和结论,基于ResNet和Feature Pyramid Net(FPN)设计了一种新的one-stage检测框架.RetinaNet 是由一个骨干网络和两个特定任务子网组成的单一网络。骨感网络负责在整个输入图像上计算卷积特征图,并且是一个现成的卷积网络。
- 第一个子网在骨干网络的输出上执行卷积对象分类(small FCN attached to each FPN level)子网的参数在所有金字塔级别共享
- 第二个子网执行卷积边界框回归(attach another samll FCN to each pyramid level)
- 对象分类子网和框回归子网,尽管共享一个共同的结构,使用单独的参数。
Anchors:
在金字塔等级P3到P7上,锚点的面积分别为$32^{2}$到$512^{2}$, 使用的长宽比为[1:2,1:1,2:1]. 对于更密集的比例覆盖,每个级别添加锚点的尺寸$[2^{0},2^{\frac{1}{3}},2^{\frac{1}{2}}]$
IOU:
[0,0.4)的为背景,[0.4,0.5)的忽略,大于0.5的为前景
Two Stage
R-FCN Object Detection via Region-based Fully Convolutional Networks
R-FCN 通过添加 Position-sensitive score map 解决了把 ROI pooling 放到网络最后一层降低平移可变性的问题,以此改进了 Faster R-CNN 中检测速度慢的问题。
PS:
分类需要特征具有平移不变性,检测则要求对目标的平移做出准确响应。论文中作者给了测试的数据:ROI放在ResNet-101的conv5后,mAP是68.9%;ROI放到conv5前(就是标准的Faster R-CNN结构)的mAP是76.4%,差距是巨大的,这能证明平移可变性对目标检测的重要性。
Faster R-CNN检测速度慢的问题,速度慢是因为ROI层后的结构对不同的proposal是不共享的,试想下如果有300个proposal,ROI后的全连接网络就要计算300次, 非常耗时。
模型: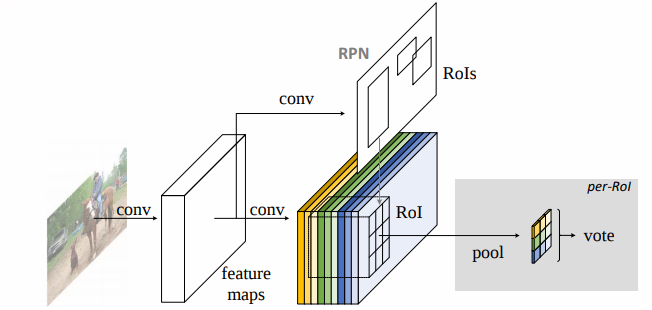
- Backbone architecture: ResNet-101有100个卷积层,后面是全局平均池化和1000类的全连接层。删除了平均池化层和全连接层,只使用卷积层来计算特征映射。最后一个卷积块是2048维,附加一个随机初始化的1024维的1×1卷积层来降维
- $k^{2}(C+1)$Conv: ResNet101的输出是W*H*1024,用$k^{2}(C+1)$个1024*1*1的卷积核去卷积即可得到$k^{2}(C+1)$个大小为W*H的position sensitive的score map。这步的卷积操作就是在做prediction。k = 3,表示把一个ROI划分成3*3,对应的9个位置
- ROI pooling: 一层的SPP结构。主要用来将不同大小的ROI对应的feature map映射成同样维度的特征
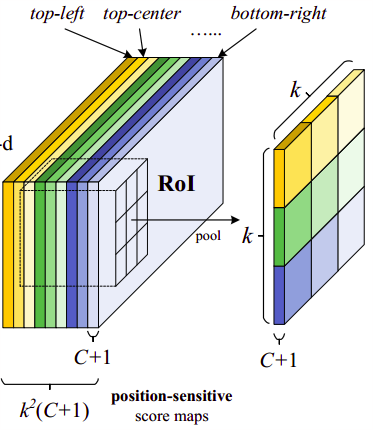
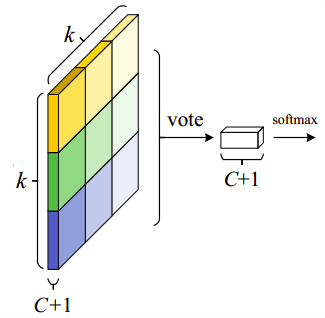
- Vote:k*k个bin直接进行求和(每个类单独做)得到每一类的score,并进行softmax得到每类的最终得分,并用于计算损失
训练:
- 损失函数: $L(s,t_{x,y,w,h})=L_{cls}(s_{c^{\star}}+ \lambda [c^{\star}>0]L_{reg}(t,t^{\star})$
将正样本定义为与真实边界框IOU至少为0.5的ROI,否则为负样本 - 在线难例挖掘(OHEM): 其主要考虑训练样本集总是包含较多easy examples而相对较少hard examples,而自动选择困难样本能够使得训练更为有效,此外还有:S-OHEM: Stratified Online Hard Example Mining for Object Detection. S-OHEM 利用OHEM和stratified sampling技术。其主要考虑OHEM训练过程忽略了不同损失分布的影响,因此S-OHEM根据分布抽样训练样本。A-Fast-RCNN: Hard positive generation via adversary for object detection从更好的利用数据的角度出发,OHEM和S-OHEM都是发现困难样本,而A-Fast-RCNN的方法则是通过GAN的方式在特征空间产生具有部分遮挡和形变的困难样本。
- 空洞和步长:我们的全卷积架构享有FCN广泛使用的语义分割的网络修改的好处。特别的是,将ResNet-101的有效步长从32像素降低到了16像素,增加了分数图的分辨率。第一个conv5块中的stride=2操作被修改为stride=1,并且conv5阶段的所有卷积滤波器都被“hole algorithm” 修改来弥补减少的步幅.
位置敏感分数图:
我们可以想想一下这种情况,M 是一个 5*5 大小,有一个蓝色的正方形物体在其中的特征图,我们将方形物体平均分割成 3*3 的区域。现在我们从 M 中创建一个新的特征图并只用其来检测方形区域的左上角。这个新的特征图如下右图,只有黄色网格单元被激活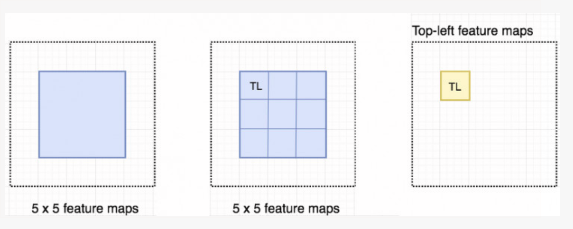
因为我们将方形分为了 9 个部分,我们可以创建 9 张特征图分别来检测对应的物体区域。因为每张图检测的是目标物体的子区域,所以这些特征图被称为位置敏感分数图(position-sensitive score maps)。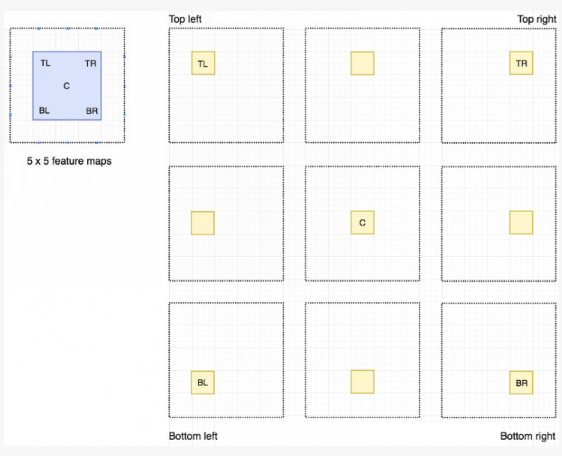
比如,我们可以说,下图由虚线所画的红色矩形是被提议的 ROIs 。我们将其分为 3*3 区域并得出每个区域可能包含其对应的物体部分的可能性。我们将此结果储存在 3*3 的投票阵列(如下右图)中。比如,投票阵列 [0][0] 中数值的意义是在此找到方形目标左上区域的可能性。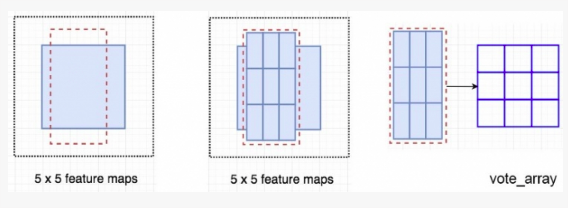
将分数图和 ROIs 映射到投票阵列的过程叫做位置敏感 ROI 池化(position-sensitive ROI-pool)。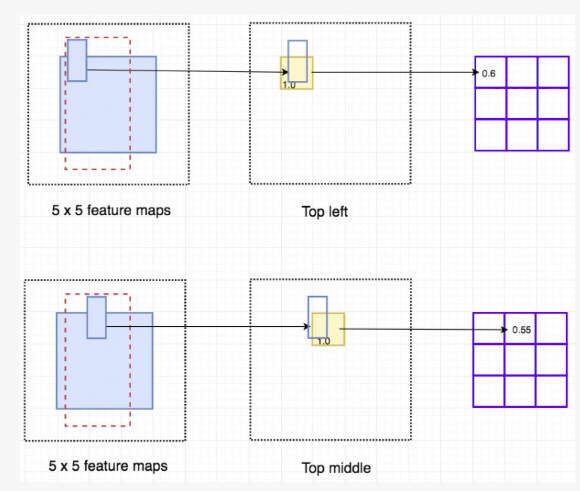
在计算完位置敏感 ROI 池化所有的值之后,分类的得分就是所有它元素的平均值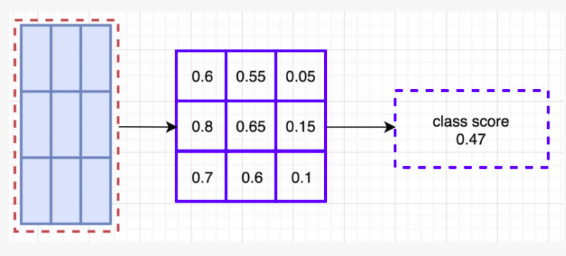
如果说我们有 C 类物体需要检测。我们将使用 C+1个类,因为其中多包括了一个背景(无目标物体)类。每类都分别有一个 3×3 分数图,因此一共有 (C+1)×3×3 张分数图。通过使用自己类别的那组分数图,我们可以预测出每一类的分数。然后我们使用 softmax 来操作这些分数从而计算出每一类的概率。
FPN Feature Pyramid Networks for Object Detection
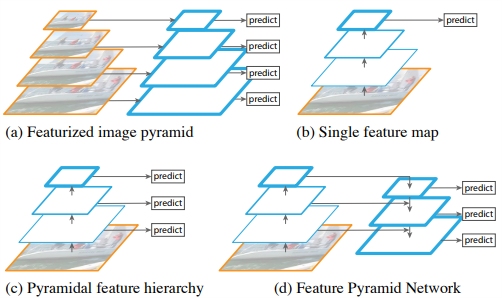
a. 通过缩放图片获取不同尺度的特征图
b. ConvNET
c. 通过不同特征分层
d. FPN
特征金字塔网络FPN,网络直接在原来的单网络上做修改,每个分辨率的 feature map 引入后一分辨率缩放两倍的 feature map 做 element-wise 相加的操作。通过这样的连接,每一层预测所用的 feature map 都融合了不同分辨率、不同语义强度的特征,融合的不同分辨率的 feature map 分别做对应分辨率大小的物体检测。这样保证了每一层都有合适的分辨率以及强语义特征。同时,由于此方法只是在原网络基础上加上了额外的跨层连接,在实际应用中几乎不增加额外的时间和计算量。
FPN: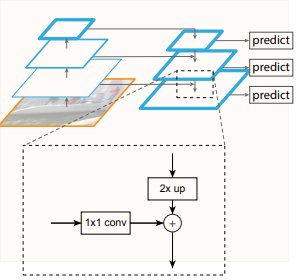
- 图中feature map用蓝色轮廓表示,较粗的表示语义上较强特征
- 采用的bottom-up 和 top-down 的方法, bottom-up这条含有较低级别的语义但其激活可以更精确的定位因为下采样的次数更少。 Top-down的这条路更粗糙但是语义更强。
- top-down的特征随后通过bottom-up的特征经由横向连接进行增强如图,使用较粗糙分辨率的特征映射时候将空间分辨率上采样x2倍。bottom-up的特征要经过1x1卷积层来生成最粗糙分辨率映射。
- 每个横向连接合并来自自下而上路径和自顶向下路径的具有相同空间大小的特征映射。

RPN结合FPN
- 通过用FPN替换单尺度特征映射来适应RPN。在特征金字塔的每个层级上附加一个相同设计的头部(3x3 conv(目标/非目标二分类和边界框回归)和 两个1x1convs(分类和回归))由于头部在所有金字塔等级上的所有位置密集滑动,所以不需要在特定层级上具有多尺度锚点。相反,为每个层级分配单尺度的锚点。定义锚点$[P_{2},P_{3},P_{4},P_{5},P_{6}]$分别具有$[32^{2},64^{2},128^{2},256^{2},512^{2}]$个像素 面积,以及多个长宽比{1:2,1:1,2:1}所以总共15个锚点在金字塔上。
- 其余同RPN网络
- 不同的尺度ROI用不同层的特征,每个box根据公式计算后提取其中某一层特征图对应的特征ROI,大尺度就用后面一些的金字塔层(P5),小尺度就用前面一点的层(P4)
可根据公式:$k=[k_{0}+log_{2}(\frac{\sqrt{wh}}{224}]$ 计算需要哪一层的特征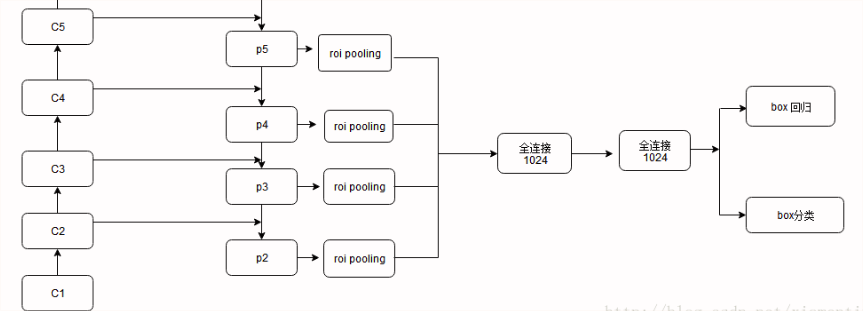
Light-Head R-CNN: In Defense of Two-Stage Object Detector
two-stage 的方法在本身的一个基础网络上都会附加计算量很大的一个用于 classification+regression 的网络,导致速度变慢
- Faster R-CNN: two fully connected layers for RoI recognition
- R-FCN: produces a large score maps.
因此,作者为了解决 detection 的速度问题,提出了一种新的 two-stage detector,就是Light-Head R-CNN。速度和准确率都有提升。Light-Head R-CNN 重点是 head 的结构设计。包括两部分: R-CNN subnet(ROI pooling 之后的network) 和ROI warping。
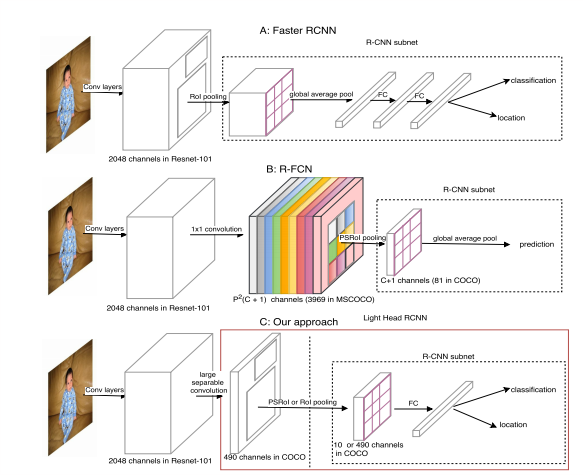
方法
- Thin feature map:
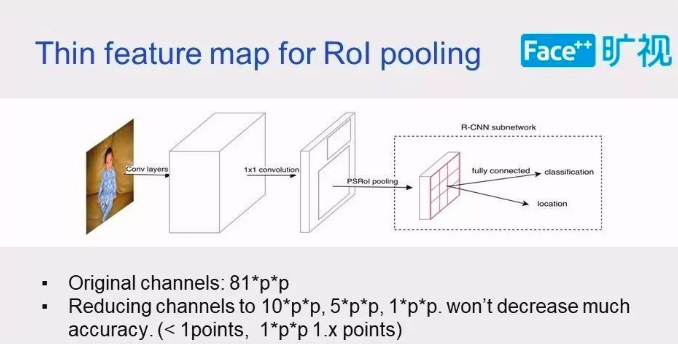 降低进入head部分feature map的channel数也就是将r-fcn的score map从$P\times P(C+1)$减小到$P\times P\times \alpha$,$\alpha$是一个与类别数无关且较小的值,比如10。这样,score map的channel数与类别数无关,使得后面的分类不能像r-fcn那样vote,于是在roi pooling之后添加了一个fc层进行预测类别和位置。
降低进入head部分feature map的channel数也就是将r-fcn的score map从$P\times P(C+1)$减小到$P\times P\times \alpha$,$\alpha$是一个与类别数无关且较小的值,比如10。这样,score map的channel数与类别数无关,使得后面的分类不能像r-fcn那样vote,于是在roi pooling之后添加了一个fc层进行预测类别和位置。 - Large separable convolution:
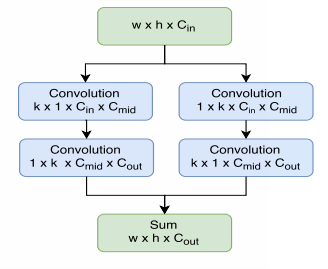
- Cheap R-CNN:
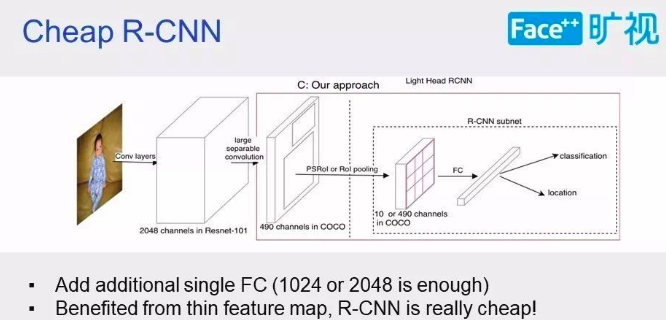
模型:
- Large: (1) ResNEt-101; (2) atrous algorithm; (3) RPN chanels 512; (4) Large separable convolution with $C_{mid}=256$
- Small: (1) Xception like; (2) abbandon atrous algorithm; (3) RPN convolution to 256; (4) Large separable convolution with $C_{mid}=64$; (5) Apply PSPooling with alignment techniques as RoI warping(better results involve RoI-align).
