Image Segmentation
Introduction
在计算机视觉领域,图像分割(Segmentation)指的是将数字图像细分为多个图像子区域(像素的集合)(也被称作超像素)的过程。图像分割的目的是简化或改变图像的表示形式,使得图像更容易理解和分析。图像分割通常用于定位图像中的物体和边界(线,曲线等)。更精确的,图像分割是对图像中的每个像素加标签的一个过程,这一过程使得具有相同标签的像素具有某种共同视觉特性。
图像分割的结果是图像上子区域的集合(这些子区域的全体覆盖了整个图像),或是从图像中提取的轮廓线的集合(例如边缘检测)。一个子区域中的每个像素在某种特性的度量下或是由计算得出的特性都是相似的,例如颜色、亮度、纹理。邻接区域在某种特性的度量下有很大的不同。
应用
- 医学影像:1. 肿瘤和其他病理的定位;2. 组织体积的测量;3. 计算机引导的手术;4. 诊断;5. 治疗方案的定制;6. 解剖学结构的研究
- 卫星图像中定位物体
- 人脸识别
- 指纹识别
- 交通控制系统
Tranditional Methods
- 基于阙值的分割方法: 1. 固定阙值分割;2. 直方图双峰法;3. 迭代阙值图像分割;自适应阙值图像分割(最大分类方差法,均值法,最佳阙值).
- 基于边缘的分割方法: 1. Canny边缘检测器;2. Harris角点检测器;3. SIFT检测器;3. SURF检测器.
- 基于区域的分割方法: 1. 种子区域生长法;2. 区域分裂合并法;3. 分水岭法.
- 基于图论的分割方法: 1. GraphCut; 2. GrabCut; 3. Random Walk.
- 基于能量泛函的分割方法: 参数活动轮廓模型(1. Snake模型;2. Active Shape Model; 3. Active Apperance Models; 4. Constrained local model);几何活动轮廓模型.
Datasets
- Pascal VOC: 20个类别,6929张标注图片
- CityScapes:道路驾驶场景,30个类别,5000张精细标注,20000张粗糙标注
- MS COCO:80类,33万张图片,超过20万张有标注,150万个物体的个体
- 医学影像领域的ImageNet: DeepLesion, 10000多个病例研究的超过32000个病变标注
图像分割的度量标准
假设共有$k+1$个类(从$L_{o}$到$L_{k}$,其中包含一个空类或背景), $P_{ij}$表示本属于类i但被预测为类j的像素数量。即,$p_{ii}$表示真正的数量,而$p_{ij}$和$p_{ji}$则分别被解释为假正和假负,尽管两者都是假正与假负之和。
- Pixel Accuracy(PA, 像素精度): 最简单的度量,为标记正确的像素占总像素的比例。
$$PA=\frac{\sum_{i=0}^{k}p_{ii}}{\sum_{i=0}^{k}\sum_{j=0}^{k}p_{ij}}$$ - Mean Pixel Accuracy(MAP,均像素精度): PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。
$$MAP=\frac{1}{k+1}\sum_{i=0}^{k}\frac{p_{ii}}{\sum_{j=0}^{k}p_{ij}}$$ - Mean Intersection over Union(MIoU, 均交并比): 为语义分割的标准度量。其计算两个集合的交集和并集之比,这两个集合为真实值(ground truth)和预测值(predicted segmentation). 这个比例可以变形为正真数(intersection)比上真正、假负、假正(并集)之和,之后在每个类上计算IoU再平均。
$$MIoU = \frac{1}{k+1}\sum_{i=0}^{k}\frac{p_{ii}}{\sum_{j=0}^{k}p_{ij}+\sum_{j=0}^{k}(p_{ji}-p_{ii})}$$ - Frequency Weighted Intersection over Union(FWIoU, 频权交并比): 为MIoU的一种提升,根据每个类出现的频率为其设置权重。
$$FWIoU = \frac{1}{\sum_{i=0}^{k}\sum_{j=0}^{k}p_{ij}}\sum_{i=0}^{k}\frac{p_{ii}}{\sum_{j=0}^{k}p_{ij}+\sum_{j=0}^{k}(p_{ji}-p_{ii})}$$
深度学习算法
Fully Convolutional Networks
论文地址
传统神经网络做分类的步骤是,首先是一个图像进来之后经过多层卷积得到降维之后的特征图,这个特征图经过全连接层变成一个分类器,最后输出一个类别的向量,这就是分类的结果。
而 FCN 是把所有的全连接层换成卷基层,原来只能输出一个类别分类的网络可以在特征图的每一个像素输出一个分类结果。这样就把分类的向量,变成了一个分类的特征图。
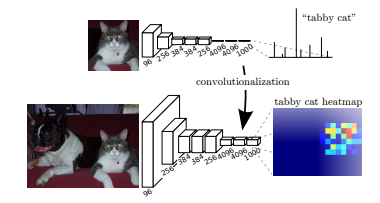
上图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。而FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
全连接->卷积层:
一个 K=4096 的全连接层,输入数据体的尺寸是 7∗7∗512,这个全连接层可以被等效地看做一个 F=7,P=0,S=1,K=4096 的卷积层.
假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
- 针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
- 针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
- 对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
end to end, pixels to pixels network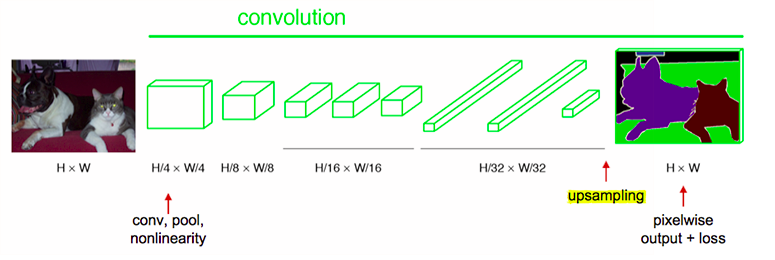
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到$\frac{H}{32} \times \frac{W}{32}$的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是最重要的高维特征图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。最后的输出是1000张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片,如上图右侧有狗狗和猫猫的图。
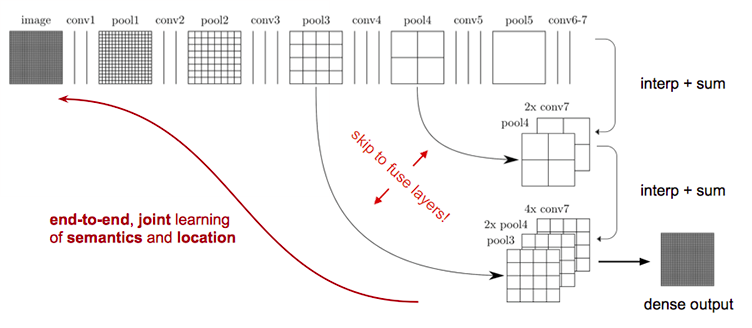
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个插值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。
缺点:
- 是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
- 是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
补充:插值法
上采样upsampling的主要目的是放大图像,几乎都是采用内插值法,即在原有图像像素的基础上,在像素点值之间采用合适的插值算法插入新的元素。
线性插值法:
使用连接两个已知量的直线来确定在这个两个已知量之间的一个未知量的值的方法。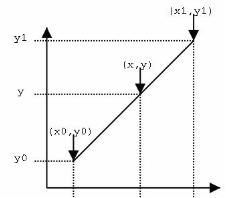
该直线方程可表示为:$\frac{y-y_{0}}{y_{1}-y_{0}}=\frac{x-x_{0}}{x_{1}-x_{0}}$ 假设方程两边的值是$\alpha$,那么这个值就是插值系数,即$\alpha =\frac{y-y_{0}}{y_{1}-y_{0}}=\frac{x-x_{0}}{x_{1}-x_{0}}$. 所以y可以表示为: $y=(1-\alpha)y_{0}+\alpha y_{1} = (1-\frac{x-x_{0}}{x_{1}-x_{0}})y_{0}+\frac{x-x_{0}}{x_{1}-x_{0}}y_{1}=\frac{x_{1}-x}{x_{1}-x_{0}}y_{0}+\frac{x-x_{0}}{x_{1}-x_{0}}y_{1}=\frac{x_{1}-x}{x_{1}-x_{0}}f(x_{1})+\frac{x-x_{0}}{x_{1}-x_{0}}f(x_{0})$双线性插值
双线性插值是插值算法中的一种,是线性插值的扩展。利用原图像中目标点四周的四个真实存在的像素值来共同决定目标图中的一个像素值,其核心思想是在两个方向分别进行一次线性插值。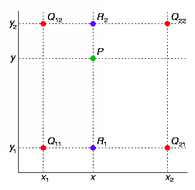
X方向的线性插值:在$Q_{12}$,$Q_{22}$中插入蓝色点$R_{2}$,$Q_{11}$,$Q_{21}$中插入蓝色点$R_{1}$
$f(R_{1}=\frac{x_{2}-x}{x_{2}-x_{1}}f(Q_{11})+\frac{x-x_{1}}{x_{2}-x_{1}}f(Q_{21})$; $f(R_{2}=\frac{x_{2}-x}{x_{2}-x_{1}}f(Q_{12})+\frac{x-x_{1}}{x_{2}-x_{1}}f(Q_{22})$
Y方向的线性插值:通过第一步计算出的$R_{1$}与$R_{2}$在y方向上插值计算出P点
$f(P)=\frac{y_{2}-y}{y_{2}-y_{1}}f(R_{1})+\frac{y-y_{1}}{y_{2}-y_{1}}f(R_{2})$
U-Net: Convolutional Networks for Biomedical Image Segmentation
论文地址
卷积网络被大规模应用在分类任务中,输出的结果是整个图像的类标签。然而,在许多视觉任务,尤其是生物医学图像处理领域,目标输出应该包括目标类别的位置,并且每个像素都应该有类标签。另外,在生物医学图像往往缺少训练图片。所以,Ciresan等人训练了一个卷积神经网络,用滑动窗口提供像素的周围区域(patch)作为输入来预测每个像素的类标签。这个网络有两个优点: 第一,输出结果可以定位出目标类别的位置; 第二,由于输入的训练数据是patches,这样就相当于进行了数据增广,解决了生物医学图像数量少的问题。
但是,这个方法也有两个很明显缺点。
第一,它很慢,因为这个网络必须训练每个patch,并且因为patch间的重叠有很多的冗余,造成资源的浪费,减慢训练时间和效率; 第二,定位准确性和获取上下文信息不可兼得。大的patches需要更多的max-pooling层这样减小了定位准确性,小的patches只能看到很小的局部信息,包含的背景信息不够。
U-Net Architecture
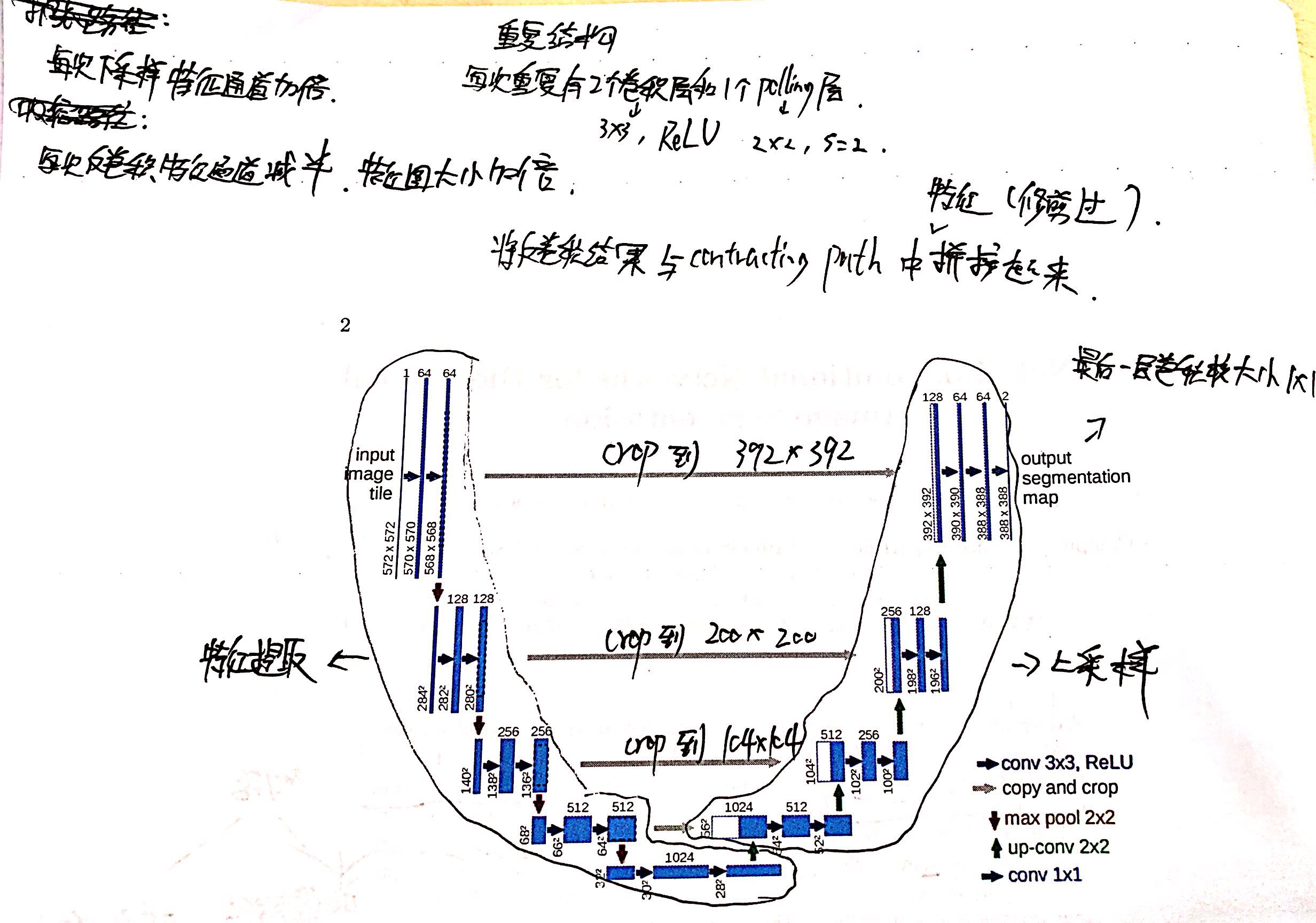
- 使用全卷积神经网络。(全卷积神经网络就是卷积取代了全连接层,全连接层必须固定图像大小而卷积不用,所以这个策略使得,你可以输入任意尺寸的图片,而且输出也是图片,所以这是一个端到端的网络。)
- 左边的网络是收缩路径:使用卷积和maxpooling。
- 右边的网络是扩张路径:使用上采样产生的特征图与左侧收缩路径对应层产生的特征图进行concatenate操作。(pooling层会丢失图像信息和降低图像分辨率且是不可逆的操作,对图像分割任务有一些影响,对图像分类任务的影响不大,为什么要做上采样?因为上采样可以补足一些图片的信息,但是信息补充的肯定不完全,所以还需要与左边的分辨率比较高的图片相连接起来(直接复制过来再裁剪到与上采样图片一样大小),这就相当于在高分辨率和更抽象特征当中做一个折衷,因为随着卷积次数增多,提取的特征也更加有效,更加抽象,上采样的图片是经历多次卷积后的图片,肯定是比较高效和抽象的图片,然后把它与左边不怎么抽象但更高分辨率的特征图片进行连接)。
- 最后再经过两次反卷积操作,生成特征图,再用两个1X1的卷积做分类得到最后的两张heatmap,例如第一张表示的是第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax类,选择它作为输入给交叉熵进行反向传播训练。
Overlap-tile strategy
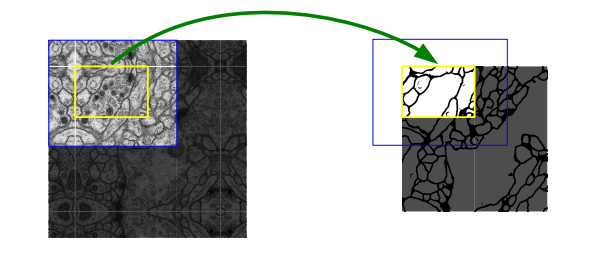
医学图像是一般相当大,但是分割时候不可能将原图太小输入网络,所以必须切成一张一张的小patch,在切成小patch的时候,Unet由于网络结构原因适合有overlap的切图,可以看图,红框是要分割区域,但是在切图时要包含周围区域,overlap另一个重要原因是周围overlap部分可以为分割区域边缘部分提供文理等信息。可以看黄框的边缘,分割结果并没有受到切成小patch而造成分割情况不好。
训练
最后一层使用了交叉熵函数与softmax:
$$E=\sum_{x\in \Omega}w(x)log(p_{\ell(x)}(x))$$
并且为了补偿训练每个类像素的不同频率使得网络更注重学习相互接触的细胞之间的小的分割边界,引入了权重图计算$w(x)$:
$$w(x)=w_{c}(x)+w_{0} \times exp(-\frac{(d_{1}(x)+d_{2}(x))}{2\sigma^{2}})$$
Data Augmentation
在只有少量样本的情况况下,要想尽可能的让网络获得不变性和鲁棒性,数据增加是必不可少的。因为本论文需要处理显微镜图片,我们需要平移与旋转不变性,并且对形变和灰度变化鲁棒。将训练样本进行随机弹性形变是训练分割网络的关键。使用随机位移矢量在粗糙的3*3网格上产生平滑形变(smooth deformations)。 位移是从10像素标准偏差的高斯分布中采样的。然后使用双三次插值(Bicubic interpolation)计算每个像素的位移。在contracting path的末尾采用drop-out 层更进一步增加数据。
双三次插值
在这种方法中,函数f在点(x,y)的值可以通过矩形网络中最近的16个采样点加权平均得到。
DeepLab V1
DeepLab是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法.
DCNN在图像标记任务中存在两个技术障碍:
- 信号下采样
- 空间不敏感(invariance)
第一个问题涉及到:在DCNN中重复最大池化和下采样带来的分辨率下降问题,分辨率的下降会丢失细节。DeepLab是采用的atrous(带孔)算法扩展感受野,获取更多的上下文信息。
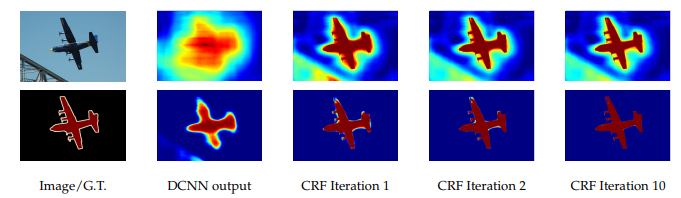
第二个问题涉及到:分类器获取以对象中心的决策是需要空间变换的不变性,这天然的限制了DCNN的定位精度,DeepLab采用完全连接的条件随机场(DenseCRF)提高模型捕获细节的能力。
除空洞卷积和 CRFs 之外,论文使用的 tricks 还有 Multi-Scale features。其实就是 U-Net 和 FPN 的思想,在输入图像和前四个最大池化层的输出上附加了两层的 MLP,第一层是 128 个 3×3 卷积,第二层是 128 个 1×1 卷积。最终输出的特征与主干网的最后一层特征图融合,特征图增加 5×128=640 个通道。实验表示多尺度有助于提升预测结果,但是效果不如 CRF 明显。
CRF->语义分割
对于每个像素位置$i$具有隐变量$x_{i}$(这里隐变量就是像素的真实类别标签,如果预测结果有21类,则$(i \in 1,2,..,21)$ 还有对应的观测值 $y_{i}$(即像素点对应的颜色值)。以像素为节点,像素与像素间的关系作为边,构成了一个条件随机场(CRF)。通过观测变量$y_{i}$来推测像素位置$i$应的类别标签$x_{i}$.条件随机场示意图如下:
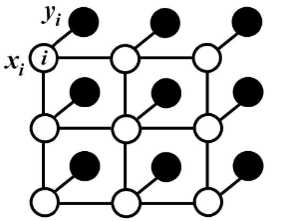
条件随机场符合吉布斯分布(x是上面的观测值,下面省略全局观测I):
$$p(x|I)=\frac{1}{Z}exp(-E(x|I))$$
全连接的CRF模型使用的能量函数$E(x)$为:
$$E(x)=\sum_{i} \theta_{i}(x_{i})+\sum_{ij}\theta_{ij}(x_{i},x_{j})$$
这分为一元势函数$\theta_{i}(x_{i})$和二元势函数$\theta_{ij}(x_{i},x_{j})$两部分
- 一元势函数是定义在观测序列位置i的状态特征函数,用于刻画观测序列对标记变量的影响(例如在城市道路任务中,观测到像素点为黑色,对应车子的可能比天空可能要大)。这里$P(x_{i})$是取DCNN计算关于像素i的输出的标签分配概率.
$$\theta_{i}(x_{i})=-logP(x_{i})$$
- 二元势函数是定义在不同观测位置上的转移特征函数,用于刻画变量之间的相关关系以及观测序列对其影响。如果比较相似,那可能是一类,否则就裂开,这可以细化边缘。一般的二元势函数只取像素点与周围像素之间的边,这里使用的是全连接,即像素点与其他所有像素之间的关系。
$$\theta_{ij}(x_{i},x_{j})=\mu(x_{i},x_{j})\sum_{m=1}^{K}w_{m}k^{m}(f_{i},f_{j})$$
DeepLab中高斯核采用双边位置和颜色的组合(第一核取决于像素位置(p)和像素颜色强度(I),第二核取决于像素位置(p)):
$$w_{1}exp(-\frac{\lVert p_{i}-p_{j} \rVert^{2}}{2\sigma_{\alpha}^{2}}-\frac{\lVert I_{i}-I_{j} \rVert^{2}}{2\sigma_{\beta}^{2}})+w_{2}exp(-\frac{\lVert p_{i}-p_{j} \rVert^{2}}{2\sigma_{\gamma}^{2}})$$
实验
| 项目 | 设置 |
|---|---|
| 数据集 | PASCAL VOC 2012 segmentation benchmark |
| DCNN模型 | 权重采用预训练的VGG16 |
| DCNN损失函数 | 交叉熵 |
| 训练器 | SGD,batch=20 |
| 学习率 | 初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1 |
| 权重 | 0.9的动量, 0.0005的衰减 |
DepLab V2
DeepLabv2 是相对于 DeepLabv1 基础上的优化。DeepLabv1 在三个方向努力解决,但是问题依然存在:
- 特征分辨率的降低
- 物体存在多尺度
- DCNN 的平移不变性
针对这三个问题, DeepLabv2做出了3个主要贡献:
- 首先,强调使用空洞卷积,作为密集预测任务的强大工具。空洞卷积能够明确地控制DCNN内计算特征响应的分辨率,即可以有效的扩大感受野,在不增加参数量和计算量的同时获取更多的上下文。
- 其次,提出了空洞空间卷积池化金字塔(atrous spatial pyramid pooling (ASPP)),以多尺度的信息得到更强健的分割结果。ASPP并行的采用多个采样率的空洞卷积层来探测,以多个比例捕捉对象以及图像上下文。
- 最后,通过组合DCNN和概率图模型,改进分割边界结果。在DCNN中最大池化和下采样组合实现可平移不变性,但这对精度是有影响的。通过将最终的DCNN层响应与全连接的CRF结合来克服这个问题。
步骤
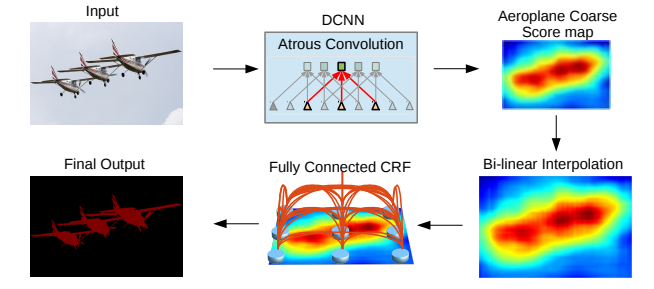
- 输入经过改进的DCNN(带空洞卷积和ASPP模块)得到粗略预测结果,即
Aeroplane Coarse Score map - 通过双线性插值扩大到原本大小,即
Bi-linear Interpolation - 再通过全连接的CRF细化预测结果,得到最终输出
Final Output
方法
空洞卷积用于密集特征提取和扩大感受野
首先考虑一维信号,空洞卷积输出为$y[i]$, 输入为$x[i]$, 长度K的滤波器为$w[k]$, 则定义为:
$$y[k]=\sum_{k=1}^{K}x[i+r\cdot k]w[k]$$
输入采样的步幅为参数r, 标准采样率是$r=1$如图(a); 图(b)是采样率$r=2$的时候: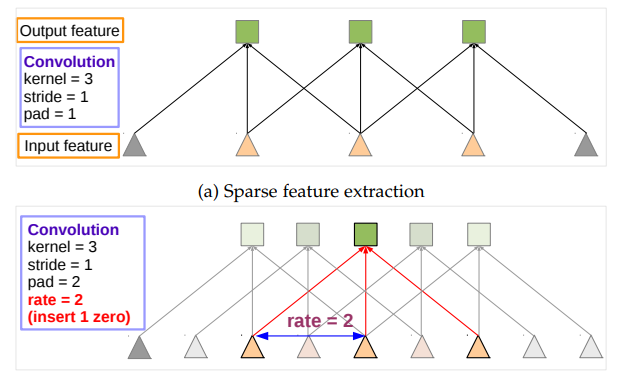
二维信号(图片)上使用空洞卷积的表现,给定一个图像:
- 上分支:首先下采样将分辨率降低2倍,做卷积。再上采样得到结果。本质上这只是在原图片的1/4内容上做卷积响应。
- 下分支:如果将全分辨率图像做空洞卷积(采样率为2,核大小与上面卷积核相同),直接得到结果。这样可以计算出整张图像的响应,如下图所示,这样做效果更佳。
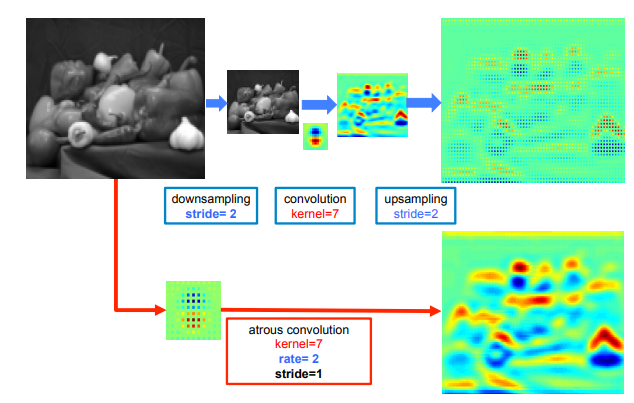
空洞卷积能够放大滤波器的感受野,速率r引入$r-1$个零,有效将感受野从$k\times k$扩展到$k_{e}=k+(k-1)(r-1)$而不增加参数和计算量。在DCNN中,常见的做法是混合使用空洞卷积以高的分辨率(理解为采样密度)计算最终的DCNN网络响应。
使用ASPP模块表示多尺度图像
DeepLabv2的做法与SPPNet类似,并行的采用多个采样率的空洞卷积提取特征,再将特征融合,类似于空间金字塔结构,形象的称为Atrous Spatial Pyramid Pooling (ASPP)。示意图如下:
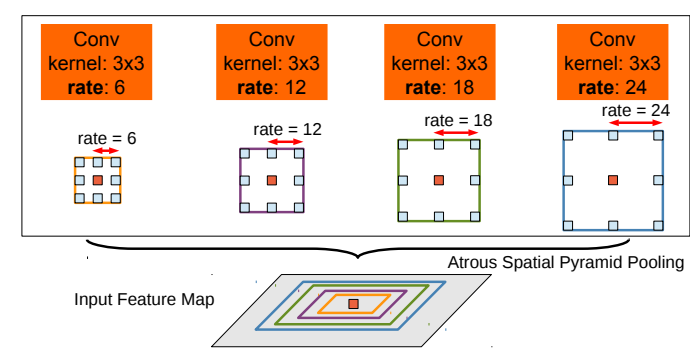
在同一Input Feature Map的基础上,并行的使用4个空洞卷积,空洞卷积配置为$r=6,12,18,24$, 核大小为$3 \times 3$. 最终将不同卷积层得到的结果做像素加融合到一起.
使用全连接CRF做结构预测用于恢复边界精度
训练
| 项目 | 设置 |
|---|---|
| DCNN模型 | 权重采用预训练的VGG16,ResNet101 |
| DCNN损失函数 | 输出的结果与ground truth下采样8倍做像素交叉熵 |
| 训练器 | SGD,batch=20 |
| 学习率 | 初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1 |
| 权重 | 0.9的动量, 0.0005的衰减 |
DepLab V3
语义分割任务,在应用深度卷积神经网络中的有两个挑战:
- 第一个挑战:连续池化和下采样,让高层特征具有局部图像变换的内在不变性,这允许DCNN学习越来越抽象的特征表示。但同时引起的特征分辨率下降,会妨碍密集的定位预测任务,因为这需要详细的空间信息。
- 第二个挑战:多尺度目标的存在
DeepLabv3的主要贡献在于:
- 重新讨论了空洞卷积的使用,在级联模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息。
- 改进了ASPP模块:由不同采样率的空洞卷积和BN层组成,尝试以级联或并行的方式布局模块。
- 讨论了一个重要问题:使用大采样率的空洞卷积,因为图像边界响应无法捕捉远距离信息,会退化为1×1的卷积, 因此建议将图像级特征融合到ASPP模块中。
- 阐述了训练细节并分享了训练经验,论文提出的”DeepLabv3”改进了以前的工作,获得了很好的结果
方法
- 空洞卷积应用于密集的特征提取
深层次的空洞卷积
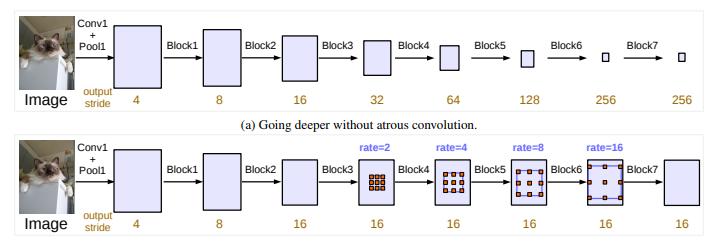

将空洞卷积应用在级联模块, 取ResNet中最后一个block,在上图中为block4,并在其后面增加级联模块。图(a)所示,整体图片的信息总结到后面非常小的特征映射上,使用步幅越长的特征映射,得到的结果反倒会差,结果最好的out_stride = 8 需要占用较多的存储空间。因为连续的下采样会降低特征映射的分辨率,细节信息被抽取,这对语义分割是有害的。上图(b)所示,可使用不同采样率的空洞卷积保持输出步幅的为out_stride = 16.这样不增加参数量和计算量同时有效的缩小了步幅。
Atrous Spatial Pyramid Pooling
对于在DeepLabv2中提出的ASPP模块,其在特征顶部映射图并行使用了四种不同采样率的空洞卷积。这表明以不同尺度采样是有效的,在DeepLabv3中向ASPP中添加了BN层。不同采样率的空洞卷积可以有效的捕获多尺度信息,但是,随着采样率的增加,滤波器的有效权重(权重有效的应用在特征区域,而不是填充0)逐渐变小。如下图所示:
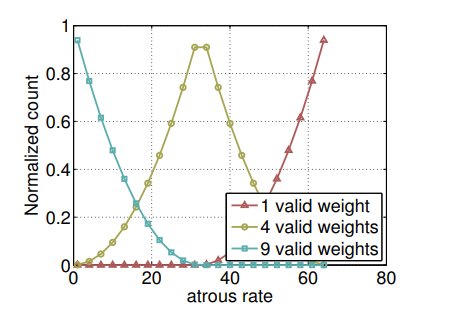
当不同采样率的$3 \times 3$卷积核应用在$65 \times 65$的特征映射上,采样率接近特征映射大小时,$3 \times 3$的滤波器不是捕捉全图像的上下文,而是退化为简单的$1 \times 1$滤波器,只有滤波器中心点的权重起了作用。
为了克服这个问题,改进了ASPP结构如上图:- 一个$1 \times 1$卷积和三个$3 \times 3$卷积的采样率为$rate = (6,12,18)$的空洞卷积,滤波器数量为256,包含BN层。针对output_stride=16的情况。(当output_stride=8的时候,采样率会加倍,所有的特征会通过$1 \times 1$卷积级联到一起)
- 使用了图片级特征。具体来说,在模型最后的特征映射上应用全局平均,将结果经过$1 \times 1$的卷积,再双线性上采样得到所需的空间维度。
训练
| 部分 | 设置 |
|---|---|
| 数据集 | PASCAL VOC 2012 |
| 工具 | TensorFlow |
| 裁剪尺寸 | 采样513大小的裁剪尺寸 |
| 学习率策略 | 采用poly策略, $learning rate = base_lr(1-\frac{iter}{max_iters})^{power}$ |
| BN层策略 | 当output_stride=16时,我们采用batchsize=16,同时BN层的参数做参数衰减0.9997。在增强的数据集上,以初始学习率0.007训练30K后,冻结BN层参数。采用output_stride=8时,再使用初始学习率0.001训练30K。训练output_stride=16比output_stride=8要快很多,因为中间的特征映射在空间上小四倍。但因为output_stride=16在特征映射上粗糙的是牺牲了精度。 |
| 上采样策略 | 在先前的工作上,将最终的输出与GroundTruth下采样8倍做比较之后发现保持GroundTruth更重要,故将最终的输出上采样8倍与完整的GroundTruth比较。 |
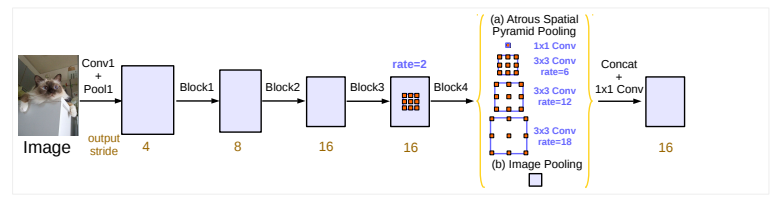
DepLab-V$3^{+}$
因为深度网络存在pooling or convolutions with stride的层,会导致feature分辨率下降,从而导致预测精度降低,而造成的边界信息丢失问题. 这个问题可以通过使用空洞卷积替代更多的pooling层来获取分辨率更高的feature。但是feature分辨率更高会极大增加运算量。
方法
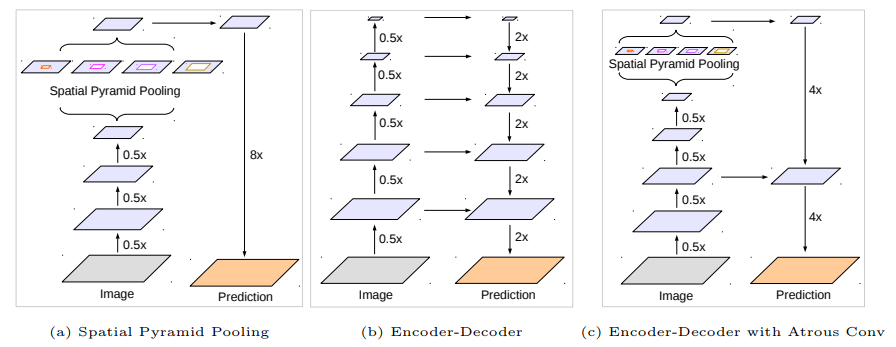
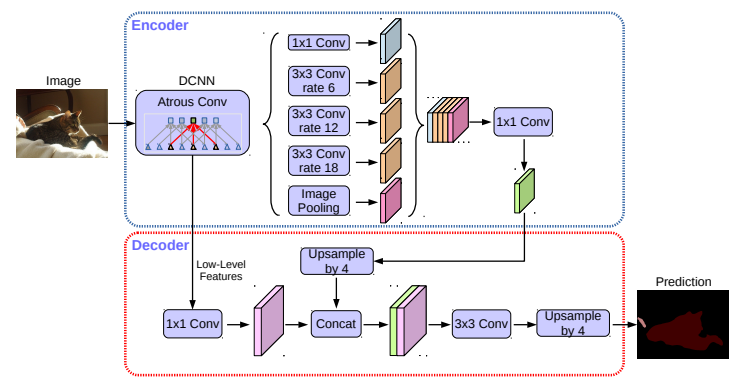
所以DeepLabV$3^{+}$中通过采用了encoder-decoder结构,在DeepLab V3中加入了一个简单有效的decoder模块来改善物体边缘的分割结果(图c):先上采样4倍,在与encoder中的特征图concatenate,最后在上采样4倍恢复到原始图像大小。除此之外还尝试使用Xception作为encoder,在Atrous Spatial Pyramid Pooling和decoder中应用depth-wise separable convolution得到了更快精度更高的网络。
Encoder
- ResNet: encoder就是DeepLab V3,通过修改ResNet101最后两(一)个block的stride,使得output stride为8(16)。之后在block4后应用改进后的Atrous Spatial Pyramid Pooling,将所得的特征图concatenate用1×1的卷积得到256个通道的特征图。
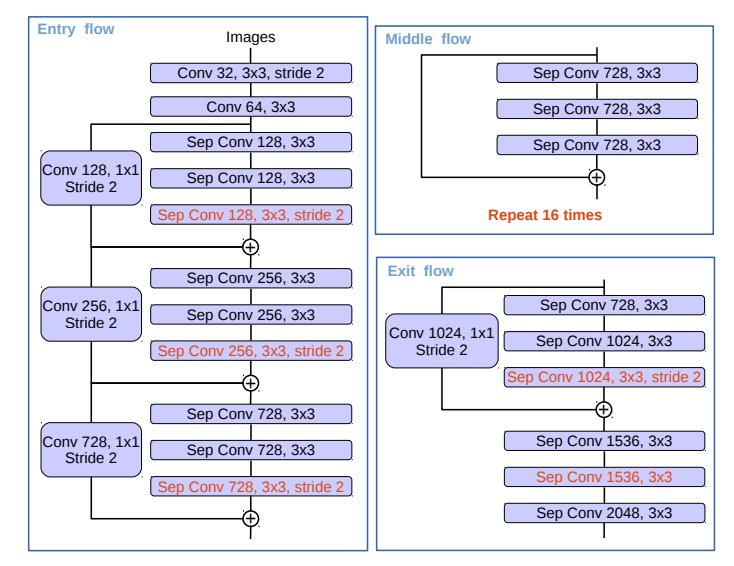
Xecption: 采用的Xception模型为MSRA team提出的改进的Xception,叫做Aligned Xception,并做了几点修改:
- 网络深度与Aligned Xception相同,不同的地方在于为了快速计算和有效的使用内存而不修改entry flow network的结构。
- 所有的max pooling操作替换成带stride的separable convolution,这能使得对任意分辨率的图像应用atrous separable convolution提取特征。
- 在每个3×3的depath-wise convolution后增加BN层和ReLU。
Decoder
- 在decoder中,特征图首先上采样4倍,然后与encoder中对应分辨率低级特征concatenate。在concatenate之前,由于低级特征图的通道数通常太多(256或512),而从encoder中得到的富含语义信息的特征图通道数只有256,这样会淡化语义信息,因此在concatenate之前,需要将低级特征图通过1×1的卷积减少通道数。在concatenate之后用3×3的卷积改善特征,最后上采样4倍恢复到原始图像大小。
- 设计:
- $1 \times 1$卷积的通道数采用48
- 用来获得更锋利的边界的3×3的卷积。最后采用了2个3×3的卷积
- 使用的encoder的低级特征(Conv2)
结果:
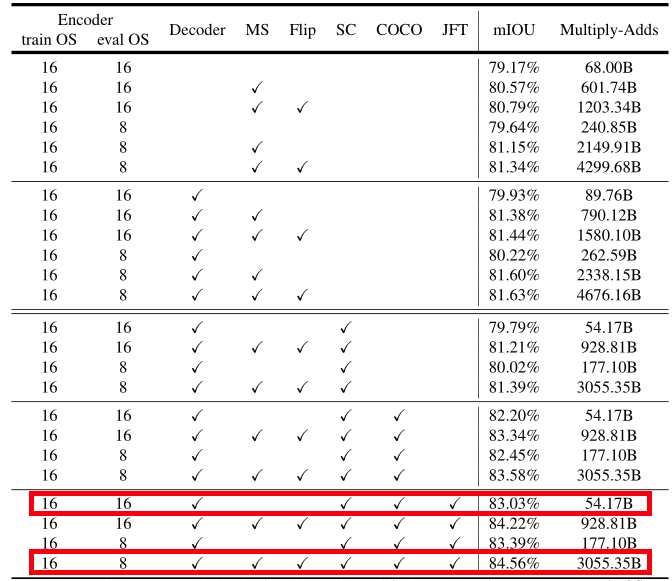
Aligned Xception改
当train_stride=16和eval_stride=8的时候mIOU最好达到了84.56% 然而计算量比较高。使用train_stride和eval_stride都为16的时候,结果下降了1.53%但是计算量下降了60倍。
