深度学习模型性能分析
在真实世界中,任何模型(例如 VGG / MobileNet 等)都必须依赖于具体的计算平台(例如CPU / GPU / ASIC 等)才能展现自己的实力。此时,模型和计算平台的”默契程度”会决定模型的实际表现。Roofline Model 提出了使用 Operational Intensity(计算强度)进行定量分析的方法,并给出了模型在计算平台上所能达到理论计算性能上限公式。
1. 计算平台的两个指标:算力 $\pi$ 与带宽 $\beta$
算力 $\pi$ :也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。单位是
FLOPSorFLOP/s。带宽 $\beta$ :也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是
Byte/s。计算强度上限 $I_{max}$ :两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是
FLOPs/Byte。
注:这里所说的“内存”是广义上的内存。对于CPU计算平台而言指的就是真正的内存;而对于GPU计算平台指的则是显存。
2. 模型的两个指标:计算量 与 访存量
计算量:指的是输入单个样本(对于CNN而言就是一张图像),模型进行一次完整的前向传播所发生的浮点运算个数,也即模型的时间复杂度。单位是
#FLOPorFLOPs。其中卷积层的计算量公式如下: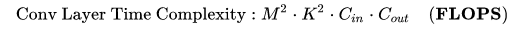
- $M$: 每个卷积核输出特征图(Feature Map)的边长
- $K$: 每个卷积核(Kernel)的边长
- $C_{in}$: 每个卷积核的通道数,也即输入通道数,也即上一层的输出通道数。
- $C_{out}$: 本卷积层具有的卷积核个数,也即输出通道数。
- 其中,输出特征图尺寸本身又由输入矩阵尺寸 $X$ 、卷积核尺寸 $K$ 、$Padding$、 $Stride$ 这四个参数所决定,表示如下:
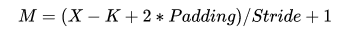
- 注1:为了简化表达式中的变量个数,这里统一假设输入和卷积核的形状都是正方形。
- 注2:严格来讲每层应该还包含 1 个 Bias 参数,这里为了简洁就省略了。
- 访存量:指的是输入单个样本,模型完成一次前向传播过程中所发生的内存交换总量,也即模型的空间复杂度。在理想情况下(即不考虑片上缓存),模型的访存量就是模型各层权重参数的内存占用(Kernel Memory)与每层所输出的特征图的内存占用(Output Memory)之和。单位是Byte。由于数据类型通常为float32 ,因此需要乘以四。
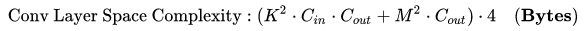
- 模型的计算强度 $I$ :由计算量除以访存量就可以得到模型的计算强度,它表示此模型在计算过程中,每
Byte内存交换到底用于进行多少次浮点运算。单位是FLOPs/Byte。可以看到,模计算强度越大,其内存使用效率越高。
- 模型的理论性能 $P$ :我们最关心的指标,即模型在计算平台上所能达到的每秒浮点运算次数(理论值)。单位是
FLOPSorFLOP/s。下面我们即将介绍的 Roof-line Model 给出的就是计算这个指标的方法。
3. Roof-line Model
其实 Roof-line Model 说的是很简单的一件事:模型在一个计算平台的限制下,到底能达到多快的浮点计算速度。更具体的来说,Roof-line Model 解决的,是计算量为A且访存量为B的模型在算力为C且带宽为D的计算平台所能达到的理论性能上限E是多少这个问题。
- 算力决定“屋顶”的高度(绿色线段)
- 带宽决定“房檐”的斜率(红色线段)
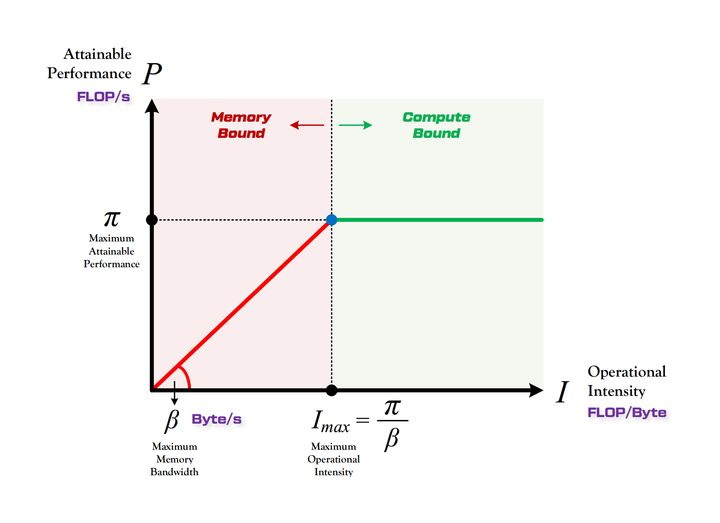
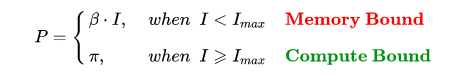
- 计算瓶颈区域
Compute-Bound
不管模型的计算强度 $I$ 有多大,它的理论性能 $P$ 最大只能等于计算平台的算力 $\pi$ 。当模型的计算强度 $I$ 大于计算平台的计算强度上限 $I_{max}$ 时,模型在当前计算平台处于 Compute-Bound状态,即模型的理论性能 $P$ 受到计算平台算力 $\pi$ 的限制,无法与计算强度 $I$ 成正比。但这其实并不是一件坏事,因为从充分利用计算平台算力的角度上看,此时模型已经完全利用了计算平台的全部算力。可见,计算平台的算力 $\pi$ 越高,模型进入计算瓶颈区域后的理论性能 $P$ 也就越大。
- 带宽瓶颈区域
Memory-Bound
当模型的计算强度 $I$ 小于计算平台的计算强度上限 $I_{max}$ 时,由于此时模型位于“房檐”区间,因此模型理论性能 $P$ 的大小完全由计算平台的带宽上限 $\beta$ (房檐的斜率)以及模型自身的计算强度 $I$ 所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽 $\beta$ 越大(房檐越陡),或者模型的计算强度 $I$ 越大,模型的理论性能 $P$ 可呈线性增长。
3. 模型实例分析
- VGG16
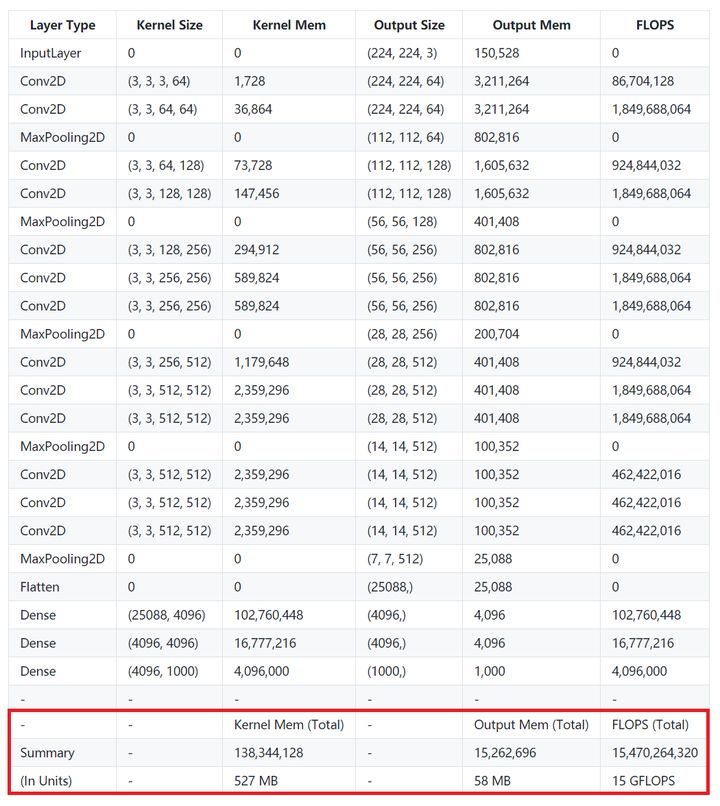
从上表可以看到,仅包含一次前向传播的计算量就达到了 15 GFLOPs,访存量则是 Kernel Mem 和 Output Mem 之和再乘以四(float),大约是 600MB。因此 VGG16 的计算强度就是 25 FLOPs/Byte。
在检测中去除FC层的话(参数量占整个模型80%)那么它的实际计算强度可以再提升四倍以上。
- MobileNet
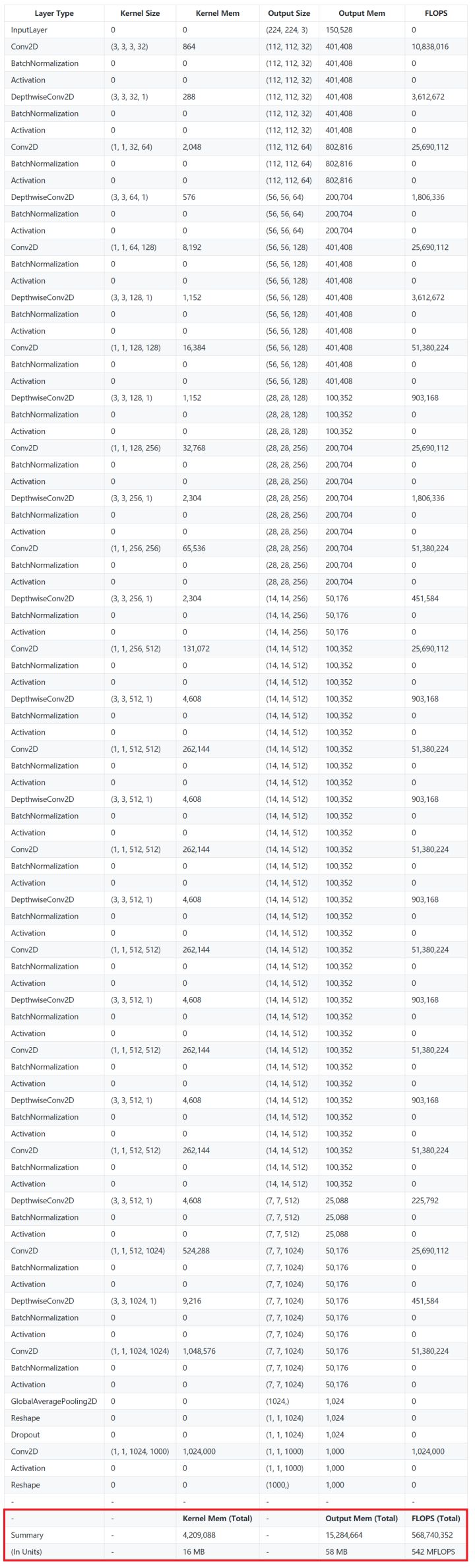
MobileNet 是以轻量著称的小网络代表。相比简单而庞大的 VGG16 结构,MobileNet 的网络更为细长,加入了大量的BN,每一层都通过 DW + PW 的方式降低了计算量,同时也付出了计算效率低的代价。
MobileNet 的计算量只有大约 0.5 GFLOPs(VGG16 则是 15 GFLOPs),其访存量也只有 74 MB(VGG16 则是约 600 MB)。这样看上去确实轻量了很多,但是由于计算量和访存量都下降了,而且相比之下计算量下降的更厉害,因此 MobileNet 的计算强度只有 7 FLOPs/Byte。
- 两个模型在 1080Ti 上的对比
1080Ti 的算力 $\pi=11.3$TFLOP/s
1080Ti 的带宽 $\beta=484$GB/s
因此 1080Ti 计算平台的最大计算强度 $I_{max}=24$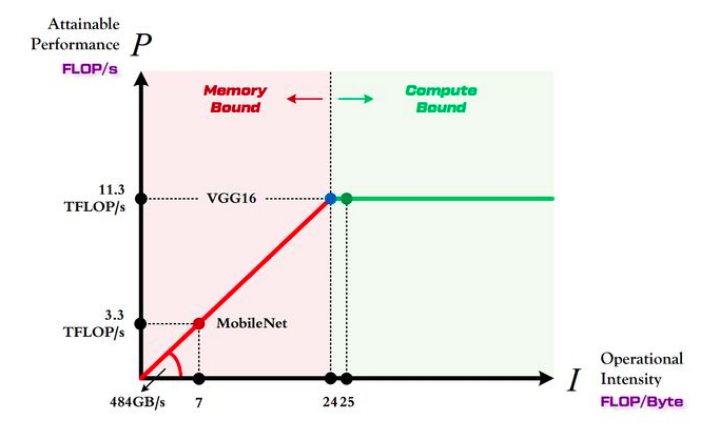
由上图可以非常清晰的看到:
- MobileNet 处于 Memory-Bound 区域。在 1080Ti 上的理论性能只有 3.3 TFLOP/s。
- VGG16 刚好迈入 Compute-Bound 区域。完全利用 1080Ti 的全部算力。
Roofline 模型讲的是程序在计算平台的算力和带宽这两个指标限制下,所能达到的理论性能上界,而不是实际达到的性能,因为实际计算过程中还有除算力和带宽之外的其他重要因素,它们也会影响模型的实际性能,这是 Roofline Model 未考虑到的。例如矩阵乘法,会因为 cache 大小的限制、GEMM 实现的优劣等其他限制,导致你几乎无法达到 Roofline 模型所定义的边界(屋顶)。
